Ключевые выводы
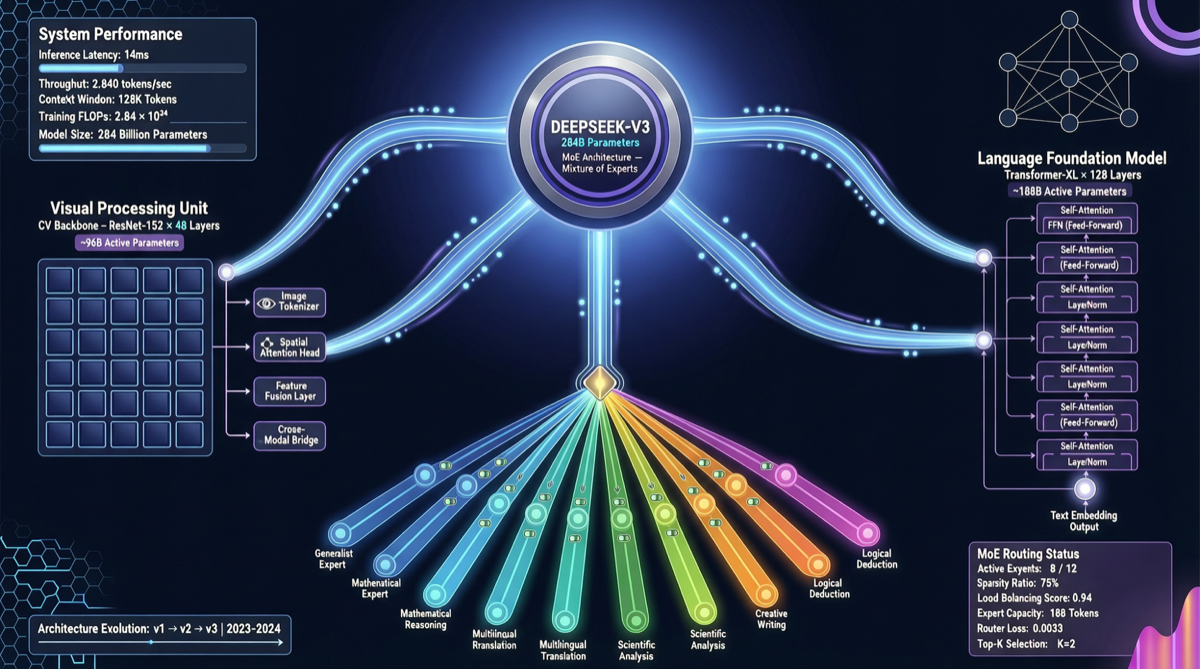
В конце апреля DeepSeek опубликовал статью о мультимодальной большой языковой модели “Thinking with Visual Primitives”, раскрыв технические детали своей унифицированной визу-языковой архитектуры. Модель построена на базе DeepSeek-V4-Flash MoE (284B общих параметров, 13B активных) и оснащена собственным визуальным энкодером DeepSeek-ViT, что знаменует важный переход китайских мультимодальных моделей от «составных решений» к «нативным архитектурам».
Разбор технической архитектуры
| Компонент | Спецификация | Ключевое решение |
|---|---|---|
| Языковая база | DeepSeek-V4-Flash | 284B общих / 13B активных параметров, архитектура MoE |
| Визуальный энкодер | DeepSeek-ViT | Разбиение на патчи 14×14, пространственное сжатие 3×3 перед подачей в LLM |
| Слияние модальностей | Нативное выравнивание токенов | Визуальные признаки напрямую отображаются в языковые токены, без проекционных слоёв |
| Режим рассуждения | Поддержка thinking | Цепочки рассуждений включены и для визуальных задач |
Ключевые инновации визуального энкодера
DeepSeek-ViT использует стратегию разбиения на патчи 14×14, аналогичную традиционным ViT, но добавляет шаг пространственного сжатия 3×3 после вывода. Это решение значительно сокращает количество визуальных токенов, снимая вычислительные ограничения при обработке длинных последовательностей — что особенно критично при работе с изображениями высокого разрешения.
Сравнение с основными решениями:
| Решение | Стратегия визуального кодирования | Сжатие токенов | Задержка |
|---|---|---|---|
| DeepSeek-ViT | 14×14 патч + сжатие 3×3 | Высокое | Низкая |
| Qwen2-VL | Динамическое разрешение | Среднее | Средняя |
| LLaVA-OneVision | Фиксированный патч | Низкое | Высокая |
| InternVL | Многоуровневые признаки | Среднее | Средняя |
Что означает «Visual Primitives»?
«Visual Primitives» в названии статьи означает, что модель разбивает визуальную информацию на базовые визуальные единицы (примитивы) для рассуждения, а не просто кодирует изображения в фиксированные векторы. Это позволяет модели выполнять точные операции с визуальными признаками в процессе рассуждения, аналогично тому, как люди сначала распознают базовые элементы (края, формы, цвета) при наблюдении за изображением, а затем комбинируют их в высокоуровневое семантическое понимание.
Почему это важно
1. Пионер мультимодального MoE
В то время как большинство open source мультимодальных моделей используют плотные архитектуры, DeepSeek впервые успешно применил архитектуру MoE к мультимодальным сценариям. При 284B общих параметров активируется только 13B, что означает сохранение мощных возможностей визуального понимания при приемлемых затратах на вычисления.
2. Сигнал стратегии open source
Публикация статьи показывает, что DeepSeek продолжает свою стратегию open source. Если веса модели будут выпущены, она станет одной из крупнейших open source мультимодальных MoE моделей по количеству параметров, напрямую конкурируя с Qwen2-VL и InternVL.
3. Связь с таймлайном выпуска V4
Текстовая модель DeepSeek V4 была выпущена в конце апреля, но получила прохладный ответ рынка. Публикация мультимодальной статьи предполагает, что продуктовая линейка DeepSeek расширяется отединственной текстовой модели к мультимодальности — что может быть стратегией дифференцированной конкуренции.
Практические рекомендации
- Исследователи: Обратите внимание на методологию статьи, особенно на сжатие визуальных токенов и маршрутизацию MoE
- Разработчики: После выпуска весов сравните производительность с Qwen2-VL на тех же бенчмарках
- Корпоративные пользователи: Рекомендуется подождать зрелости оценок сообщества перед интеграцией в производство
Если технический маршрут DeepSeek — MoE + нативное визуальное кодирование + open source — сможет материализоваться в usable веса модели, это станет бомбой в конкуренции среди китайских мультимодальных моделей.