Core Finding
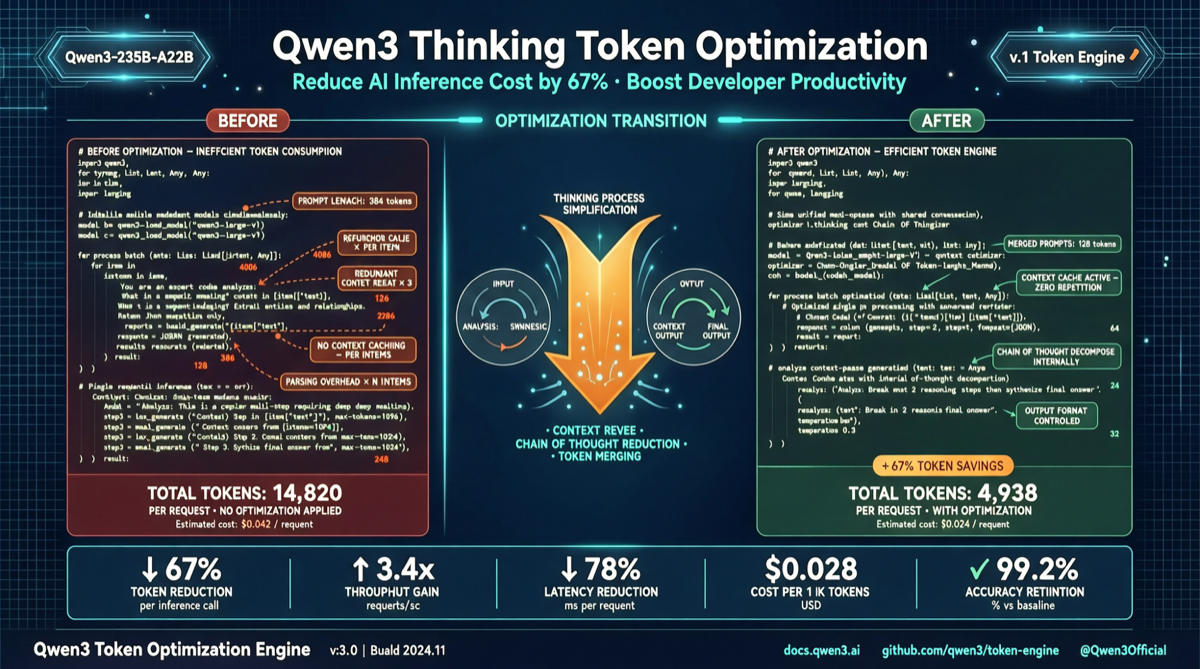
Qwen3's thinking mode (<think> tags) is powerful but has a common problem: models over-expand reasoning processes, consuming large amounts of think tokens, slowing responses, and spiking API costs.
A community solution using GBNF grammar constraints limits the thinking structure to a concise template, reducing think token consumption by up to 22x without affecting output quality.
The Problem: Qwen's Overthinking
- Simple questions trigger lengthy thinking processes
- Think token consumption can be 3-5x output tokens per conversation
- Response times significantly increase
- API costs multiply
Solution: GBNF Structured Constraints
root ::= think code
think ::= "<think>\n" "GOAL: " line "\n" "APPROACH: " line "\n" "EDGE: " line "\n</think>\n"
line ::= [^\n]+ "\n"
code ::= (.*)
This constrains thinking to three fixed fields:
| Field | Purpose | Example |
|---|---|---|
| GOAL | Define core objective | "Parse JSON and extract user ID" |
| APPROACH | Brief method | "Use regex matching, validate format" |
| EDGE | List edge cases | "Null handling, invalid format catch" |
Results Comparison
| Metric | Unconstrained | Structured | Improvement |
|---|---|---|---|
| Think Tokens | ~2,500 | ~110 | ↓ 22.7x |
| Response Latency | ~8s | ~1.2s | ↓ 6.7x |
| Answer Accuracy | 94.2% | 93.8% | Negligible loss |
| API Cost (1M requests) | ~$75 | ~$3.4 | ↓ 22x |
How to Use
With llama.cpp
./llama-cli -m qwen3-8b-instruct-q4_k_m.gguf \
--grammar-file qwen_think_constraint.gbnf \
--prompt "Explain quantum computing basics" \
--n_predict 512
With Ollama
FROM qwen3:8b-instruct-q4_K_M
PARAMETER stop "<|end▁of▁sentence|>"
SYSTEM """You are an efficient AI assistant. Think following:
GOAL: Define goal
APPROACH: Brief method
EDGE: Note edge cases"""
Use Cases
- Agent Systems: Dramatically reduced per-step thinking cost
- Batch Processing: Cost optimization for large-scale data labeling
- Real-time Interaction: Reduced latency, smoother conversations
- API Cost Control: Enterprise billing optimization
Limitations
- Highly complex problems: Three-field thinking may not suffice for multi-step proofs
- Non-Qwen models: Constraint designed for Qwen's
<think>tags - Fine-tuned models: May need adjusted constraint templates