The Cost Dilemma of Agent Evaluation
Production AI Agents require continuous evaluation and guardrails—detecting hallucinations, preventing unauthorized operations, ensuring output format correctness. Most teams use the LLM-as-Judge approach: using a large model (like GPT-5) to judge another Agent’s output quality. This approach has two prominent problems: high inference cost and large latency, plus the large model itself can miss critical errors.
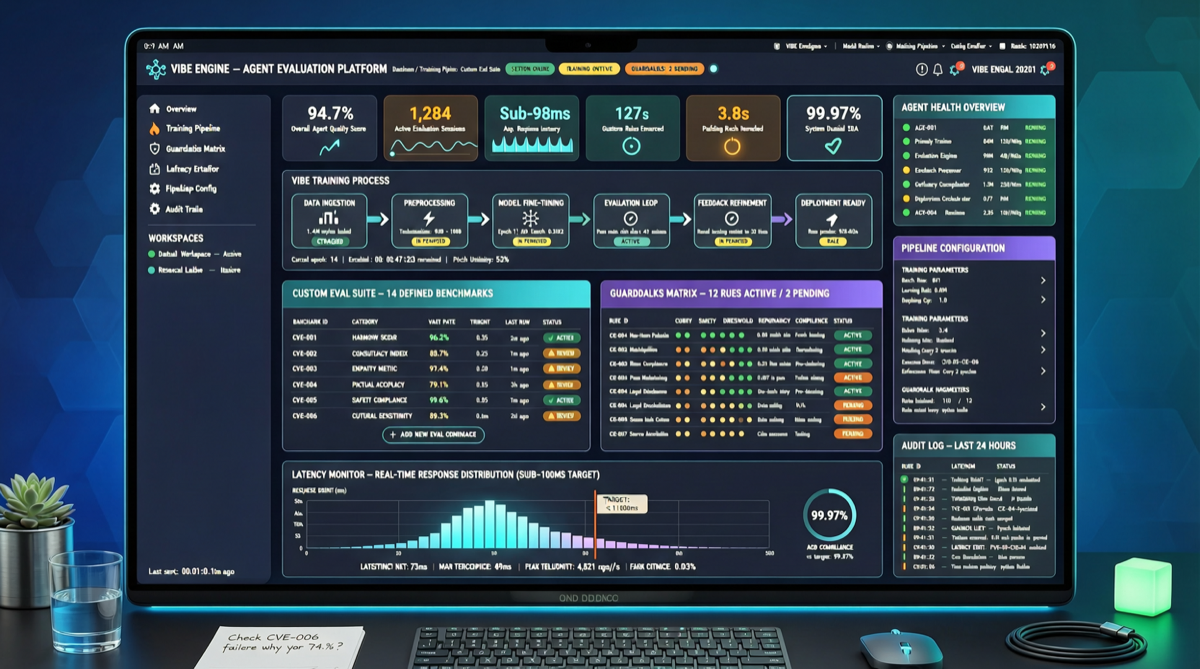
Plurai’s Vibe Training attempts to solve this with a different approach: instead of relying on a large model to judge line by line, it trains a specialized evaluator by describing “what good behavior looks like.”
Method Principles
The Vibe Training workflow consists of three steps:
- Behavior Description: Teams describe the behavioral characteristics the Agent should exhibit in natural language, e.g., “replies should not fabricate API endpoints,” “when encountering uncertain information, clearly mark it”
- Example Calibration: The system automatically selects samples from production interaction logs that best represent these behavioral characteristics, which teams review and confirm
- Deploy Evaluation Endpoint: Generates a dedicated evaluation endpoint with sub-100ms latency, directly integrable into the Agent’s runtime pipeline
The key difference from LLM-as-Judge is that the evaluator is customized for a specific Agent and specific behaviors, rather than using a general large model to cover all scenarios.
Benchmark Data
According to Plurai’s published data:
- Cost: 8x cheaper than using GPT-5-mini as a judge model
- Failure Rate: Approximately 43% reduction compared to baseline
- Latency: Sub-100ms, suitable for production real-time interception
- Deployment Time: Minutes to complete, not weeks of rule writing
These data come from Plurai’s own testing and have not yet been independently reproduced by third parties. Teams planning to adopt this approach should first verify effectiveness in low-traffic scenarios.
Comparison with Traditional Evaluation Approaches
| Dimension | LLM-as-Judge | Rule Engine | Vibe Training |
|---|---|---|---|
| Cost | High (per-call payment) | Low (one-time development) | Medium (one-time training, low-cost inference) |
| Latency | 2-10 seconds | <10ms | <100ms |
| Accuracy | Large model can miss errors | Precise but limited coverage | Scenario-optimized |
| Maintenance Cost | Low (prompt adjustment) | High (constant rule updates) | Medium (recalibration) |
| Deployment Speed | Instant | Weeks | Minutes |
Use Cases
Suitable for:
- Teams with existing production Agent running data (interaction logs)
- Scenarios requiring real-time error interception
- Medium-sized applications where LLM-as-Judge costs are too high
- Startup teams wanting to quickly deploy evaluation guardrails
Limitations:
- Requires sufficient production interaction data for training
- Limited effectiveness for brand-new Agents (no historical data)
- Evaluation result interpretability is lower than explicit rules
- Third-party independent validation has not yet appeared