何があったのか
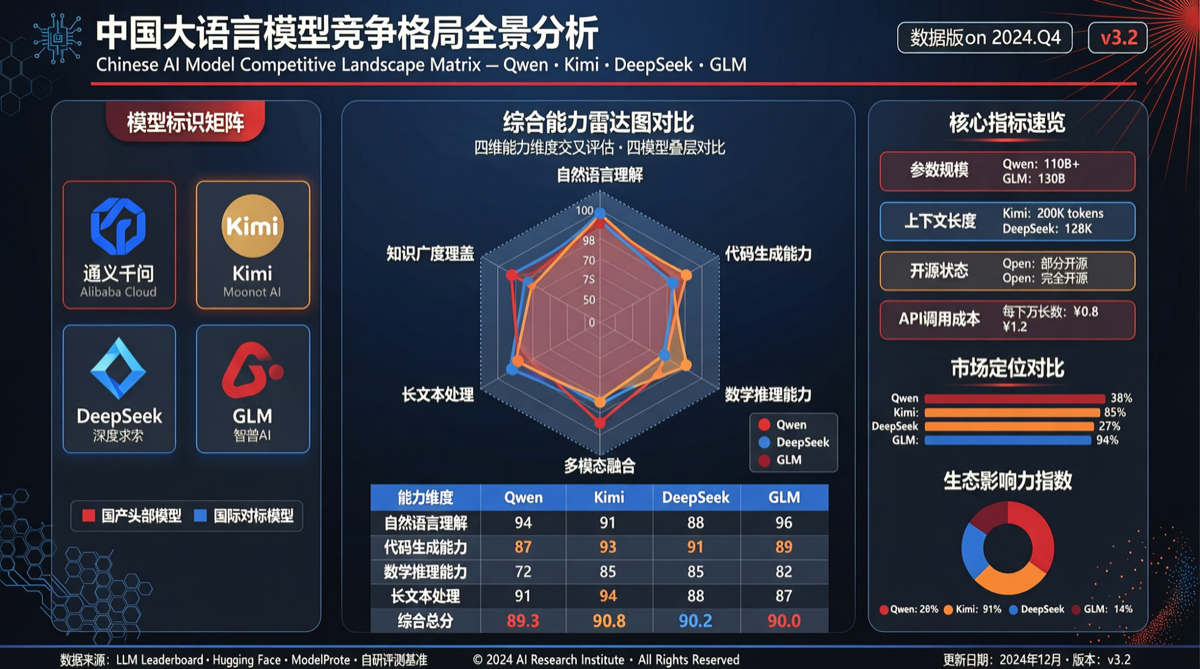
2026年5月の中国AIモデル陣営は、「単一の追従物語」から「差別化競争状況」への重要な転換期を迎えている。複数の独立したシグナルが同じ結論を指し示している:中国モデルはもはやGPTの「安価な代替品」ではなく、異なる次元でそれぞれの競争優位性を確立している。
モデルポジショニングマトリックス
| モデル | コア優位性 | 価格戦略 | 典型的なシーン | 競争ターゲット |
|---|---|---|---|---|
| Qwen3.6-Plus | コストパフォーマンス + オープンソースエコシステム | Claude Opusの約1/5 | 日常Agentワークロードの80% | Claude Sonnet |
| Kimi K2.6 | デザインとクリエイティブ能力 | 中価格帯 | Arena Designチャンピオン級パフォーマンス | GPT-4o |
| GLM-5.1 | コーディング能力 | 高価格帯 | コーディングArenaでGPT-5.5 Highを超越 | GPT-5.5 |
| DeepSeek V4 Pro | 特定ベンチマークパフォーマンス | 高い費用対効果 | FoodTruck BenchでGPT-5.2を上回る | GPT-5.2 |
| MiniMax M3 | まもなく公開、ポジショニング未定 | 未定 | 未定 | Claude Sonnet 4.8 |
重要な転換シグナル
シグナル1:GLM-5.1のコーディング能力がGPT-5.5 Highを超越
智譜GLM-5.1がコーディングArenaランキングでGPT-5.5 Highを超越——これは画期的な出来事だ。これは中国モデルがコーディング領域で「追従者」から「リーダー」へ移行したことを意味する。AIを主にプログラミングに使用するチームにとって、GLM-5.1はもはや「十分良い」代替オプションではなく、特定のシーンでの第一選択肢だ。
シグナル2:Qwen3.6-PlusのAgent費用対効果
コミュニティベンチマークテストは、Qwen3.6-PlusがClaude Opusの約5分の1の価格で日常Agentワークロードの80% を処理できることを示している。その技術アーキテクチャ——ハイブリッドスパースMoE + ネイティブ100万コンテキスト + 組み込みツールルーティング——はAgentシーン専用に最適化されている。
大量のAgentワークフローを実行するチームにとって、これは費用対効果が著しい選択肢だ。
シグナル3:Kimi K2.6のクリエイティブ優位性
月之暗面Kimi K2.6はArena Designランキングでチャンピオン級のパフォーマンスを示している。これは中国モデルの非コーディング能力における差別化を反映している——Kimiの視覚理解、クリエイティブデザイン、コンテンツ生成などのシーンでのパフォーマンスは、一部のアメリカモデルを超越しつつある。
シグナル4:DeepSeek V4 Proの垂直ベンチマーク優位
DeepSeek V4 ProはFoodTruck Benchなどの特定ベンチマークでGPT-5.2を上回るパフォーマンスを示した。これは一つのトレンドを明らかにしている:垂直シーンにおいて、中国モデルは汎用モデルよりも良いパフォーマンスを発揮する可能性がある。
アーキテクチャの違い:なぜ中国モデルは差別化するのか
中国モデルの差別化は偶然ではなく、アーキテクチャの選択とトレーニング戦略の結果だ:
| モデル | アーキテクチャ特徴 | 差別化の源泉 |
|---|---|---|
| Qwen3.6 | ハイブリッドスパースMoE + 100万コンテキスト | Agentシーンに深く最適化、ツール呼び出し効率が突出 |
| Kimi K2.6 | DeepSeek V3設計を継承 + Moonshot Muonオプティマイザー | マルチモーダルとクリエイティブ能力を強化 |
| GLM-5.1 | 大規模コーディングデータトレーニング | コーディング専門能力が突出 |
| DeepSeek V4 | 推論チェーン最適化 + 視覚プリミティブ | 推論と視覚理解能力 |
状況判斷
中国モデル陣営は差別化優位マトリックスを形成しつつあり、単一の「全面的超越」を追求するものではない。これは開発者のモデル選定にとってむしろ有利だ——異なるタスクに異なるモデルを選択するのであって、独占状態ではない。
この状況がアメリカモデルに与える影響は、「ある中国モデルがGPTを全面的に打ち負かす」ことではなく、**「各中国モデルが特定のシーンでGPTよりも適している」**ということだ。企業がタスクタイプに基づいて最適なモデルを選択できるようになると、アメリカモデルの「デフォルトオプション」地位が弱体化する。
アクション提案
- モデル選定戦略:「1つのモデルですべてを解決する」アプローチを放棄する。異なるタスクタイプ(コーディング、クリエイティブ、Agent、推論)に最に適するするモデルを選択することで、より良い費用対効果が得られる。
- Qwen3.6-Plusに適する: 大規模なAgentワークフローを実行するチーム、コストに敏感なデプロイメントシーン、オープンソースモデルのカスタマイズが必要なチーム。
- GLM-5.1に適する: プログラミングを主要用途とするチーム、GPT-5.5を超えるコーディング能力が必要なシーン。
- Kimi K2.6に適する: クリエイティブコンテンツ生成、視覚理解、デザイン支援シーン。
- DeepSeek V4 Proに適する: 高い費用対効果の推論能力が必要なシーン、特定の垂直ドメインの深いアプリケーション。
- MiniMax M3に注目: まもなく公開予定で、中国モデルの会話と汎用能力のギャップを埋める可能性がある。