Что Произошло
Лагерь китайских AI-моделей в мае 2026 года переживает критический переход от «нарратива единственного догоняющего» к «дифференцированному конкурентному ландшафту». Множество независимых сигналов указывают на один и тот же вывод: китайские модели больше не «дешёвые альтернативы» GPT — они установили свои собственные конкурентные преимущества в различных измерениях.
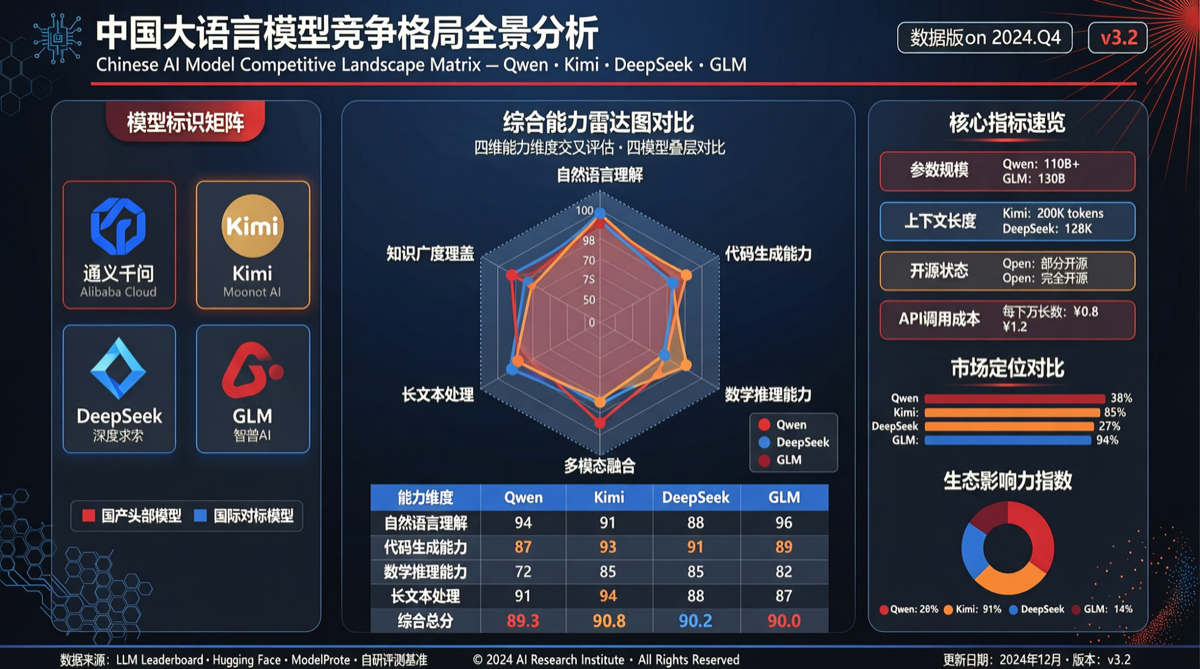
Матрица Позиционирования Моделей
| Модель | Ключевое Преимущество | Ценовая Стратегия | Типичный Сценарий | Цель Конкуренции |
|---|---|---|---|---|
| Qwen3.6-Plus | Рентабельность + экосистема с открытым кодом | ~1/5 цены Claude Opus | 80% ежедневных Agent-нагрузок | Claude Sonnet |
| Kimi K2.6 | Дизайнерские и креативные способности | Средний ценовой сегмент | Чемпионский уровень Arena Design | GPT-4o |
| GLM-5.1 | Способности кодирования | Премиум-ценообразование | Coding Arena превосходит GPT-5.5 High | GPT-5.5 |
| DeepSeek V4 Pro | Производительность в специфических бенчмарках | Высокая рентабельность | FoodTruck Bench превышает GPT-5.2 | GPT-5.2 |
| MiniMax M3 | Предстоящий релиз, позиционирование TBD | TBD | TBD | Claude Sonnet 4.8 |
Ключевые Сигналы Перехода
Сигнал Первый: Способности Кодирования GLM-5.1 Превосходят GPT-5.5 High
Zhipu GLM-5.1 превзошёл GPT-5.5 High в рейтинге Coding Arena — знаковое событие. Это означает, что китайские модели в области кодирования перешли от «догоняющих» к «лидерам». Для команд, в основном использующих AI для программирования, GLM-5.1 больше не вариант «достаточно хороший», а первый выбор в определённых сценариях.
Сигнал Второй: Рентабельность Agent Qwen3.6-Plus
Бенчмаркинг сообщества показывает, что Qwen3.6-Plus обрабатывает 80% ежедневных Agent-нагрузок примерно за одну пятую цены Claude Opus. Его техническая архитектура — гибридный разреженный MoE + нативный контекст 1M + встроенная маршрутизация инструментов — специально оптимизирована для Agent-сценариев.
Для команд, запускающих большие объёмы Agent-рабочих процессов, это значительно рентабельный выбор.
Сигнал Третий: Креативное Преимущество Kimi K2.6
Kimi K2.6 от Moonshot демонстрирует чемпионский уровень производительности в рейтинге Arena Design. Это отражает дифференциацию китайских моделей в не-кодирующих способностях — производительность Kimi в визуальном понимании, креативном дизайне и генерации контента превосходит некоторые американские модели.
Сигнал Четвёртый: Преимущество Вертикальных Бенчмарков DeepSeek V4 Pro
Производительность DeepSeek V4 Pro в FoodTruck Bench и других специфических бенчмарках превысила GPT-5.2. Это выявляет тенденцию: в вертикальных сценариях китайские модели могут работать лучше, чем модели общего назначения.
Архитектурные Различия: Почему Китайские Модели Дифференцируются
Дифференциация китайских моделей не случайна — это результат архитектурных выборов и стратегий обучения:
| Модель | Архитектурные Особенности | Источник Дифференциации |
|---|---|---|
| Qwen3.6 | Гибридный разреженный MoE + 1M контекст | Глубоко оптимизирован для Agent-сценариев, выдающаяся эффективность вызова инструментов |
| Kimi K2.6 | Наследует дизайн DeepSeek V3 + оптимизатор Moonshot Muon | Усиленные мультимодальные и креативные способности |
| GLM-5.1 | Обучение на масштабных данных кодирования | Выдающиеся способности, специфичные для кодирования |
| DeepSeek V4 | Оптимизация цепочки рассуждений + визуальные примитив | Способности рассуждения и визуального понимания |
Оценка Ландшафта
Лагерь китайских моделей формирует матрицу дифференцированных преимуществ, а не стремится к «всестороннему обгону» в одном направлении. Это на самом деле более выгодно для выбора моделей разработчиками — выбирайте разные модели для разных задач, а не полагайтесь на одного доминирующего игрока.
Влияние этого ландшафта на американские модели заключается не в том, что «одна китайская модель всесторонне побеждает GPT», а в том, что «каждая китайская модель более подходит, чем GPT, в специфических сценариях». Когда предприятия могут выбирать оптимальную модель на основе типа задачи, статус «варианта по умолчанию» американских моделей ослабевает.
Рекомендации к Действию
- Стратегия выбора модели: Откажитесь от подхода «использовать одну модель для всего». Выберите наиболее подходящую модель для разных типов задач (кодирование, креатив, Agent, рассуждение) для лучшей рентабельности.
- Qwen3.6-Plus подходит для: Команд, запускающих крупномасштабные Agent-рабочие процессы, сценариев развёртывания, чувствительных к затратам, команд, нуждающихся в кастомизации моделей с открытым исходным кодом.
- GLM-5.1 подходит для: Команд с программированием как основным вариантом использования, сценариев, требующих способности кодирования, превышающей GPT-5.5.
- Kimi K2.6 подходит для: Генерации креативного контента, визуального понимания, сценариев помощи в дизайне.
- DeepSeek V4 Pro подходит для: Сценариев, требующих высокой рентабельности способности рассуждения, глубоких приложений в специфических вертикальных доменах.
- Следите за MiniMax M3: Предстоящий релиз может заполнить пробел в разговорных и универсальных способностях китайских моделей.