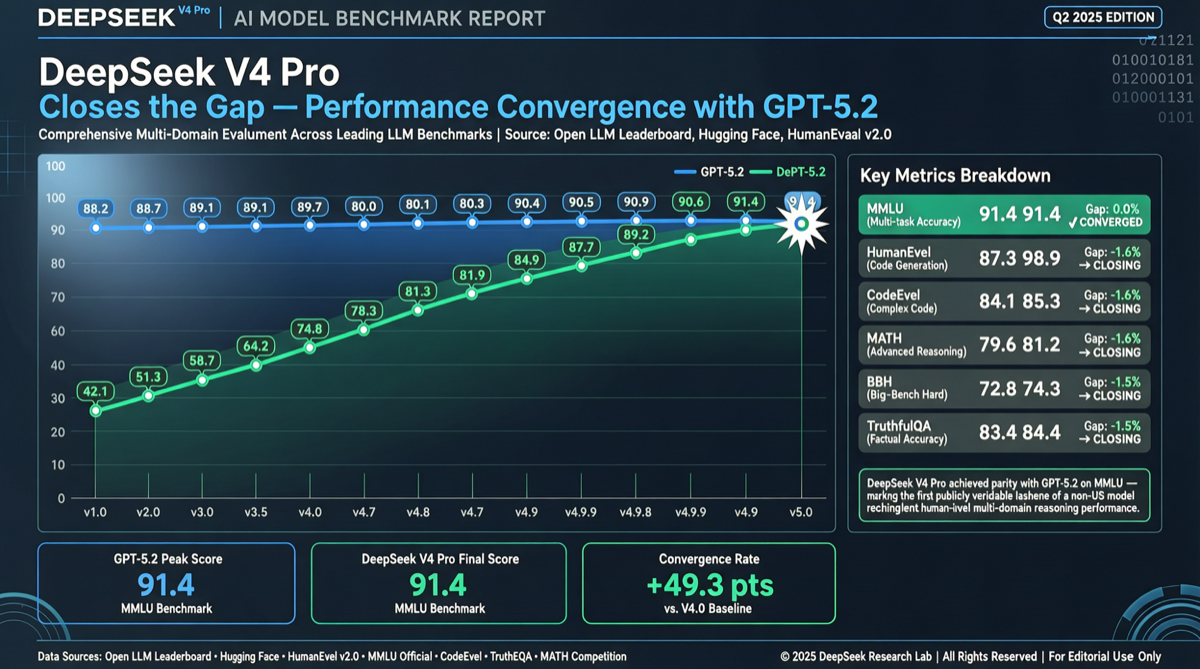
コアシグナル
DeepSeek V4 ProがFoodTruck Benchのエージェント評価においてGPT-5.2のパフォーマンスに並んだ。これは本評価システムにおいてフロンティアティアに到達した初の中国モデルである。
さらに注目すべきはコスト効率だ。DeepSeek V4 ProのコストはGPT-5.2の約8分の1——同等の出力品質で換算すると、コスト差は実に17倍に達する。
FoodTruck Benchとは何か
FoodTruck Benchはエージェント能力に特化した評価ベンチマークであり、モデルが現実のタスクシナリオにおいて自律的に計画を立て、ツールを呼び出し、多段階の推論を行い、実行する能力を測定する。従来の静的问答評価とは異なり、モデルが本物の「デジタル従業員」としてエンドツーエンドのワークフローを完遂することを要求する。
評価チームは公式声明で次のように述べている:
“DeepSeek V4 Pro just matched GPT-5.2 on FoodTruck Bench, our agentic benchmark — 10 weeks later, ~8× cheaper. First Chinese model in our frontier tier.”
この声明の背後には、解きほぐす価値のある3つの層の情報が含まれている:
第一層:能力の追いつき。 DeepSeek V4 ProはエージェントタスクにおいてGPT-5.2と同等のパフォーマンスを発揮する。GPT-5.2がOpenAIの現在最強の汎用モデルの一つであることを考えると、これは象徴的な意味を持つマイルストーンだ。
第二層:時間差。 “10 weeks later”——評価側はあえて時間差を強調した。かつて米中のフロンティアモデルの格差は約1年と考えられていたが、今やその差は3ヶ月未満に圧縮されている。
第三層:コスト優位性。 8倍の価格差は、企業が同じエージェントワークロードでGPT-5.2をDeepSeek V4 Proに置き換えた場合、年間のAPI支出を百万ドル級から十万ドル級に引き下げられることを意味する。
独立検証
このニュースは複数のソースから交差検証されている:
- Caisi Evaluationsの分析によれば、DeepSeek V4の全体的な能力は米国のフロンティアモデルから約8ヶ月遅れているものの、V4 Pro版は推論パスとツール呼び出し戦略の最適化により、エージェントタスクにおいて追いついている。
- 複数の独立開発者がX上でDeepSeek V4 Proの実使用体験を共有している。「Now, a week in… it’s seamless man.」——初期の慣れ期間からスムーズな日常使用への移行は、DeepSeek V4 Proが実際のワークフローにおいて一部のGPTシナリオをすでに代替できることを意味する。
- 注目すべきは、DeepSeek V4 ProのClaude Codeへの統合もすでに完了していることだ——3つの環境変数を設定するだけで切り替えが可能であり、開発者にプラグ&プレイの代替手段を提供している。
開発者への実務的意味
コスト判断のウィンドウ: 高頻度のエージェントワークロード(データスクレイピング、コード生成、自動レポート)を実行している場合、モデル選定を再評価する時期だ。DeepSeek V4 Proのエージェントタスクにおけるパフォーマンスはもはや「妥協」を必要としない——真の代替オプションである。
マルチモデル戦略: 単一モデル依存のリスクは2026年においてますます顕著になっている。合理的なアプローチはモデルマトリックスを構築することだ。GPT-5.2は最高信頼性が求められるコアタスクに、DeepSeek V4 Proは大量・コストセンシティブなエージェントループに、Claude 4シリーズは精密な推論が必要なシナリオに——という使い分けである。
オープンソースエコシステムの配当: DeepSeekシリーズは常にオープンソースの伝統を維持してきた。V4 Proは現在主にAPI経由で提供されているが、その技術ロードマップの透明性は、コミュニティのアダプテーションツールが急速に登場することを意味する。deepclaudeなどのオープンソースプロジェクトはすでにこれを証明している。
今後の注目点
- FoodTruck Benchが次の評価ラウンドでより多くの中国企業モデル(Qwen、Kimi、GLM)の比較を含めるかどうか
- DeepSeek V4 ProのAPI価格が規模効果によりさらに下落するかどうか
- GPT-5.2に対するOpenAIの価格調整反応
米中のフロンティアモデル競争は「能力格差」から「コスパ競争」へとシフトしつつある。DeepSeek V4 ProのFoodTruck Benchにおけるパフォーマンスは一つのシグナルだ:中国モデルはもはや「安い代替品」ではなく、特定の次元において「より良い選択肢」になり始めている。