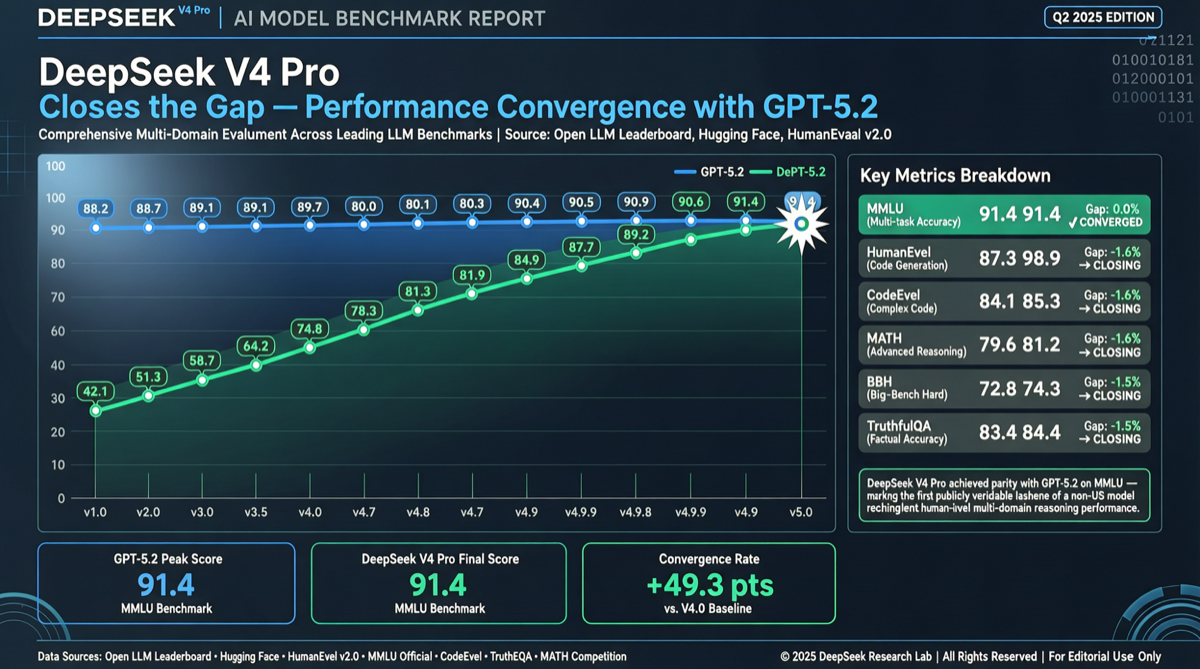
核心信号
DeepSeek V4 Pro 在 FoodTruck Bench 智能体评测中追平了 GPT-5.2 的成绩。这是该评测体系中首个进入前沿层级(frontier tier)的中国模型。
更关键的是性价比:DeepSeek V4 Pro 的成本约为 GPT-5.2 的 1/8——而实际上,如果按同等输出质量换算,成本差距甚至达到 17 倍。
FoodTruck Bench 是什么
FoodTruck Bench 是一个专注于智能体(agentic)能力的评测基准,衡量模型在真实任务场景中的自主规划、工具调用、多步推理和执行能力。与传统的静态问答评测不同,它要求模型像真正的”数字员工”一样完成端到端的工作流。
评测方在官方声明中写道:
“DeepSeek V4 Pro just matched GPT-5.2 on FoodTruck Bench, our agentic benchmark — 10 weeks later, ~8× cheaper. First Chinese model in our frontier tier.”
这句话背后有三个层次的信息值得拆解:
第一层:能力追平。 DeepSeek V4 Pro 与 GPT-5.2 在智能体任务上表现相当。考虑到 GPT-5.2 是 OpenAI 当前最强的通用模型之一,这是一个具有象征意义的里程碑。
第二层:时间差。 “10 weeks later”——评测方特意强调了时间差。曾经中美前沿模型的差距被普遍认为在一年左右,现在这个差距被压缩到了不到三个月。
第三层:成本优势。 8 倍的价差意味着,如果企业用 DeepSeek V4 Pro 替代 GPT-5.2 运行相同的智能体工作流,年度 API 支出可以从百万美元级降至十万美元级。
独立验证
这条消息得到了多方交叉验证:
- Caisi Evaluations 的分析指出,DeepSeek V4 的整体能力落后美国前沿模型约 8 个月,但 V4 Pro 版本通过优化推理路径和工具调用策略,在智能体任务上的表现已经追平。
- 多位独立开发者在 X 上分享了使用 DeepSeek V4 Pro 的实际体验:“Now, a week in… it’s seamless man.” 从最初的磨合期到现在的流畅使用,DeepSeek V4 Pro 在日常工作流中已经可以替代部分 GPT 场景。
- 值得注意的是,DeepSeek V4 Pro 在 Claude Code 中的适配也已经打通——通过三个环境变量即可完成切换,这为开发者提供了即插即用的替代方案。
对开发者的实际意义
成本决策窗口: 如果你正在运行高频的智能体工作流(数据抓取、代码生成、自动化报告),现在是重新评估模型选型的时间窗口。DeepSeek V4 Pro 在 agentic 任务上的表现已经不需要”将就”——它是真正的平替选项。
多模型策略: 单一模型依赖的风险在 2026 年愈发凸显。合理的做法是建立一个模型矩阵:GPT-5.2 处理需要最高可靠性的核心任务,DeepSeek V4 Pro 承担大批量、成本敏感的智能体循环,Claude 4 系列负责需要精细推理的场景。
开源生态红利: DeepSeek 系列模型始终保持着开源传统。V4 Pro 虽然目前主要通过 API 提供服务,但其技术路线的透明性意味着社区适配工具会快速涌现。deepclaude 等开源项目已经证明了这一点。
下一步关注
- FoodTruck Bench 是否会在下一轮评测中加入更多中国企业模型(Qwen、Kimi、GLM)的对比
- DeepSeek V4 Pro 的 API 价格是否会随规模效应进一步下调
- OpenAI 对 GPT-5.2 的价格调整反应
中美前沿模型的竞争正在从”能力差距”转向”性价比竞赛”。DeepSeek V4 Pro 在 FoodTruck Bench 上的表现是一个信号:中国模型不再只是”便宜的替代品”,而是开始在某些维度上成为”更优的选择”。