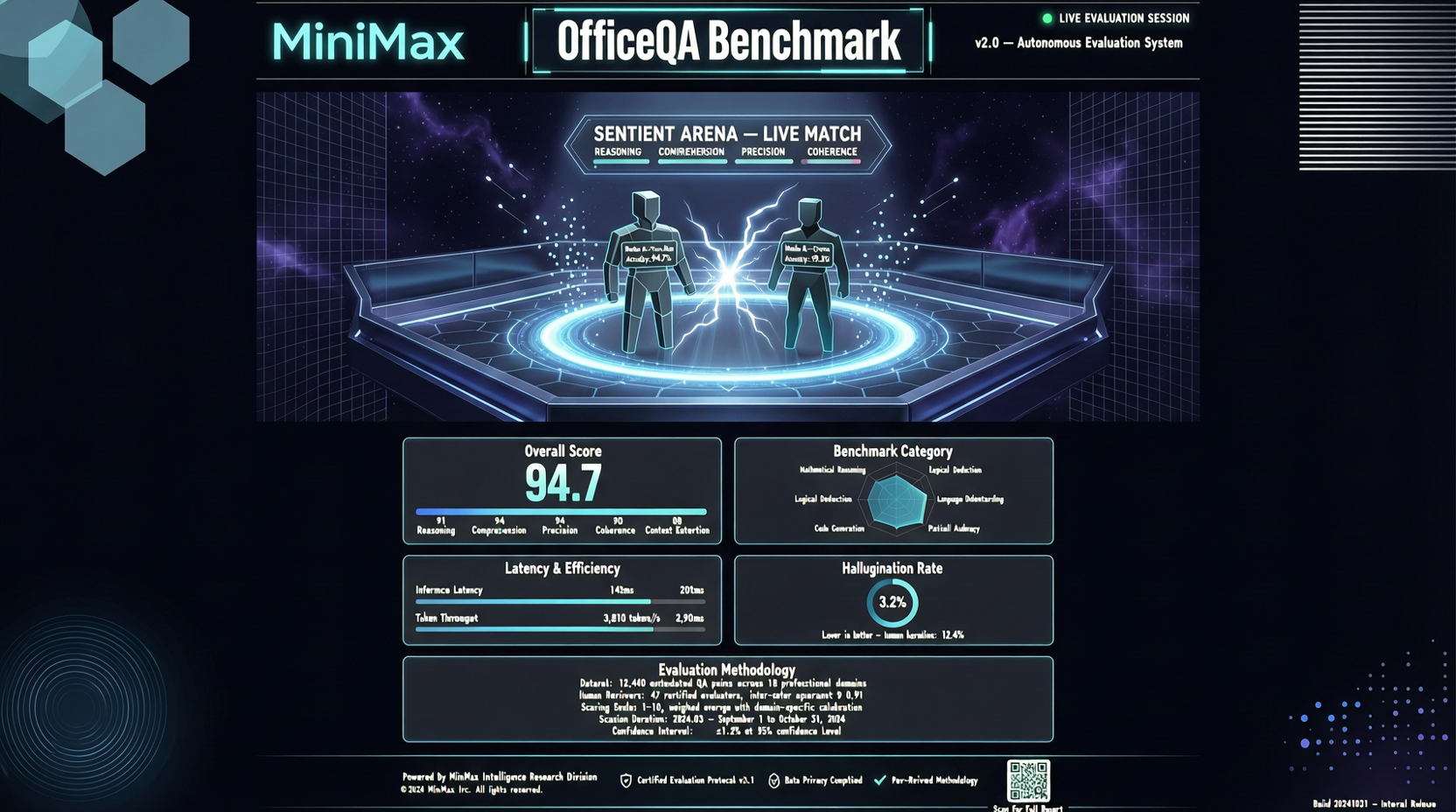
核心結論
シリコンバレーで開催されたSentient Arena AIコンテストにおいて、直感に反する結果が注目を集めた:中国のMiniMax M2.5が自社開発エージェントTellerと組み合わせ、Databricks OfficeQAベンチマークで71.5%の准确率を達成し、Claudeを上回った。
さらに注目すべきは——MiniMaxはシリコンバレーではほとんど無名であり、英語AIコミュニティではほぼ注目されていないということだ。これはまさに中国モデルの価値発見における著しい地域情報格差を示している。
イベント詳細
参加者Hermes(@0xHermes_)がシリコンバレー大会中にMiniMaxの実使用体験を共有した。主要な事実:
| 次元 | データ |
|---|---|
| モデル | MiniMax M2.5(オープンソース) |
| エージェントフレームワーク | Teller(自社開発) |
| ベンチマーク | Databricks OfficeQA |
| 准确率 | 71.5% |
| 撃破対象 | Claude(同シナリオ) |
Databricks OfficeQAは、ドキュメント処理、スプレッドシート操作、メール作成などの実務的なオフィスタスクをカバーする、オフィスソフトウェア自動化シナリオにおけるモデル能力を測定するベンチマークである。71.5%の准确率は、モデルが4分の3近いオフィスシナリオで自動化操作を確実に実行できることを意味する。
なぜMiniMaxは過小評価されているのか?
MiniMaxは中国のAIサークルである程度の認知度があるが、英語圏での知名度は極めて低い。これにはいくつかの要因が関係している:
言語の壁:MiniMaxの主要なドキュメント、コミュニティ、ユースケースは中国市場に集中しており、英語圏の開発者がその能力を発見するのは困難である。
ポジショニングの違い:DeepSeekが「低価格+オープンソース」戦略で英語コミュニティに浸透するのとも、Qwenがアリババのエコシステムによるグローバルプロモーションの恩恵を受けるのとも異なり、MiniMaxは静かに製品を磨き上げる路線を歩んでいる。
シナリオ集中:MiniMaxのオフィス自動化やマルチモーダルコンテンツ生成における最適化は、Databricks OfficeQAの評価次元とぴったり一致している。これは汎用能力での全面的な優位性ではなく、垂直シナリオにおける精密打撃である。
中国モデルのグローバル格局判断
最近の複数のシグナルを総合すると、中国モデルのグローバル競争力は分化しつつある:
| モデル | コア優勢 | 国際的認知度 |
|---|---|---|
| Qwen | コード生成効率、エコシステムの豊富さ | 高い(アリババのグローバル化) |
| DeepSeek | 推論能力、長文コンテキスト | 高い(低価格戦略) |
| Kimi | 研究ドキュメント処理 | 中(K2.6がDigitalOceanに登場) |
| MiniMax | オフィス自動化、マルチモーダル | 低い(深刻に過小評価) |
| GLM | 開発者ワークフロー | 中 |
MiniMaxのオフィスシナリオでのパフォーマンスは私たちに思い出させてくれる:評価ランキングが唯一の基準ではない。汎用ランキングで必ずしも首位に立たないモデルが、特定のシナリオでは圧倒的な優位性を持つ可能性がある。
アクション推奨
- オフィス自動化シナリオ:ドキュメント処理、スプレッドシート操作、メール自動化などのタスクを行っている場合、MiniMax M2.5は候補リストに加える価値がある。特にコストに敏感なシナリオでは。
- モデル組み合わせ戦略:1つのモデルだけに依存してはいけない。汎用推論にはClaude/GPT、オフィス自動化にはMiniMax、コーディングにはQwen——シナリオベースのモデル選択が2026年の正しい姿勢だ。
- 情報格差の機会に注目:英語コミュニティにおける中国モデルの低認知度は、開発者にとって裁定機会である。MiniMaxのような過小評価されたモデルに早期に精通することで、コンテストや製品で先行者利益を得られる可能性がある。