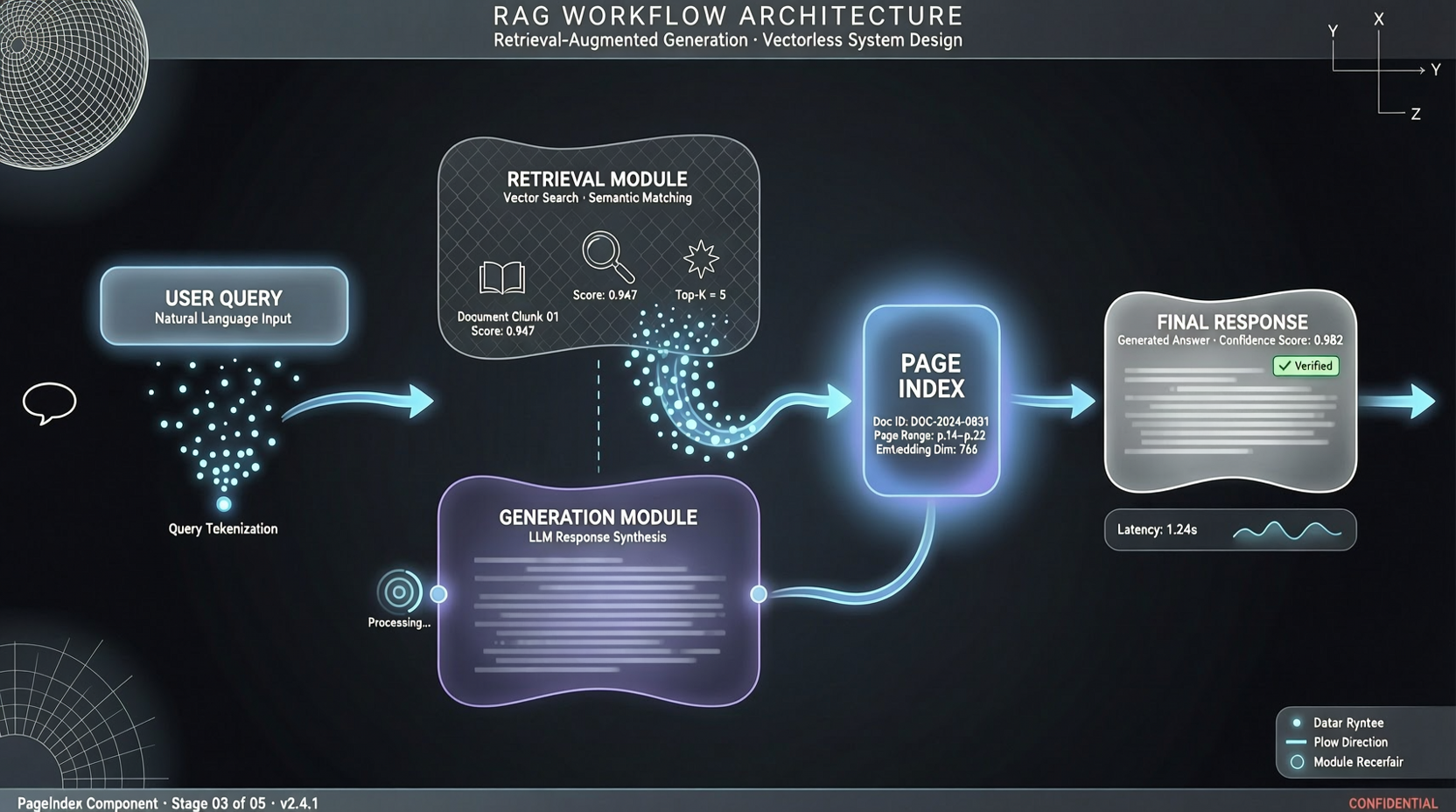
RAG(検索強化生成)は数年使われている。ほとんどの人のやり方は同じ:ドキュメントをチャンク化 → ベクトル化 → ベクトルデータベースに保存 → クエリ時に意味的類似度マッチング → 最も類似したフラグメントをLLMに投入。
このパイプラインにはずっと批判があった:ベクトル類似度は情報の関連性とイコールではない。 2つのテキストがベクトル空間で近いことと、論理的に関連していることは別問題だ。
PageIndexは違うアプローチを試したい。
何か
PageIndexはVectifyAIがオープンソース化した「ドキュメントインデックス」システム、ベクトルなし・推論ベースのRAG(Vectorless, Reasoning-based RAG)を主打とする。
コアアイデア:ベクトル化せず、ドキュメントに構造化インデックスを構築。クエリ時、ベクトル類似度で「最も似ている」フラグメントを探すのではなく、モデルにどの部分を检索すべきか推論させ、インデックスで正確に抽出する。
30,800スター、今週4,555増加。直近284コミット、最終更新は20時間前。プロジェクトのアクティビティは良好。
伝統的ベクトルRAGとの違い
| 伝統的ベクトルRAG | PageIndex | |
|---|---|---|
| インデックス方式 | ベクトル化+ベクトルDB | 構造化ドキュメントインデックス |
| 検索方式 | 意味的類似度マッチング | 推論ベース検索 |
| 依存 | ベクトルDBが必要 | ベクトルDB不要 |
| 精度 | ベクトル表現力に制限 | モデル推論能力に制限 |
要するに:「検索」环节を「マッチング問題」から「推論問題」に変えた。
メリットとデメリット
メリット:
- ベクトルデータベースのデプロイ・メンテナンスが不要、アーキテクチャが大幅に簡素化
- 正確なマッチングが必要なシナリオ(法律条項、技術ドキュメント)では、推論ベース検索が意味的類似度より正確な可能性
- インデックス更新が高速
コスト:
- 每次检索都要LLMを呼び出して推論——遅延とコストがベクトルマッチングより高い
- モデルの推論能力が十分でなければ、検索品質が直接低下
誰に向いているか
高精度检索が必要な専門領域。 法律、医療、技術ドキュメント——これらのシナリオでは「差之毫厘谬以千里」。
ベクトルデータベースをメンテナンスしたくないチーム。 ベクトルDBの運用コストは過小評価されている。
私の判断
PageIndexはベクトルRAGを「代替」しようとしているのではなく、代替パスを提供している。
2025年のRAGのキーワードは「ベクトルデータベース」。2026年は「検索戦略の多様化」になるかもしれない。
主要ソース:
- GitHub - VectifyAI/PageIndex(リポジトリ分析)
- GitHub Trending Weekly(人気追跡)
- 伝統的ベクトルRAGアーキテクチャ比較