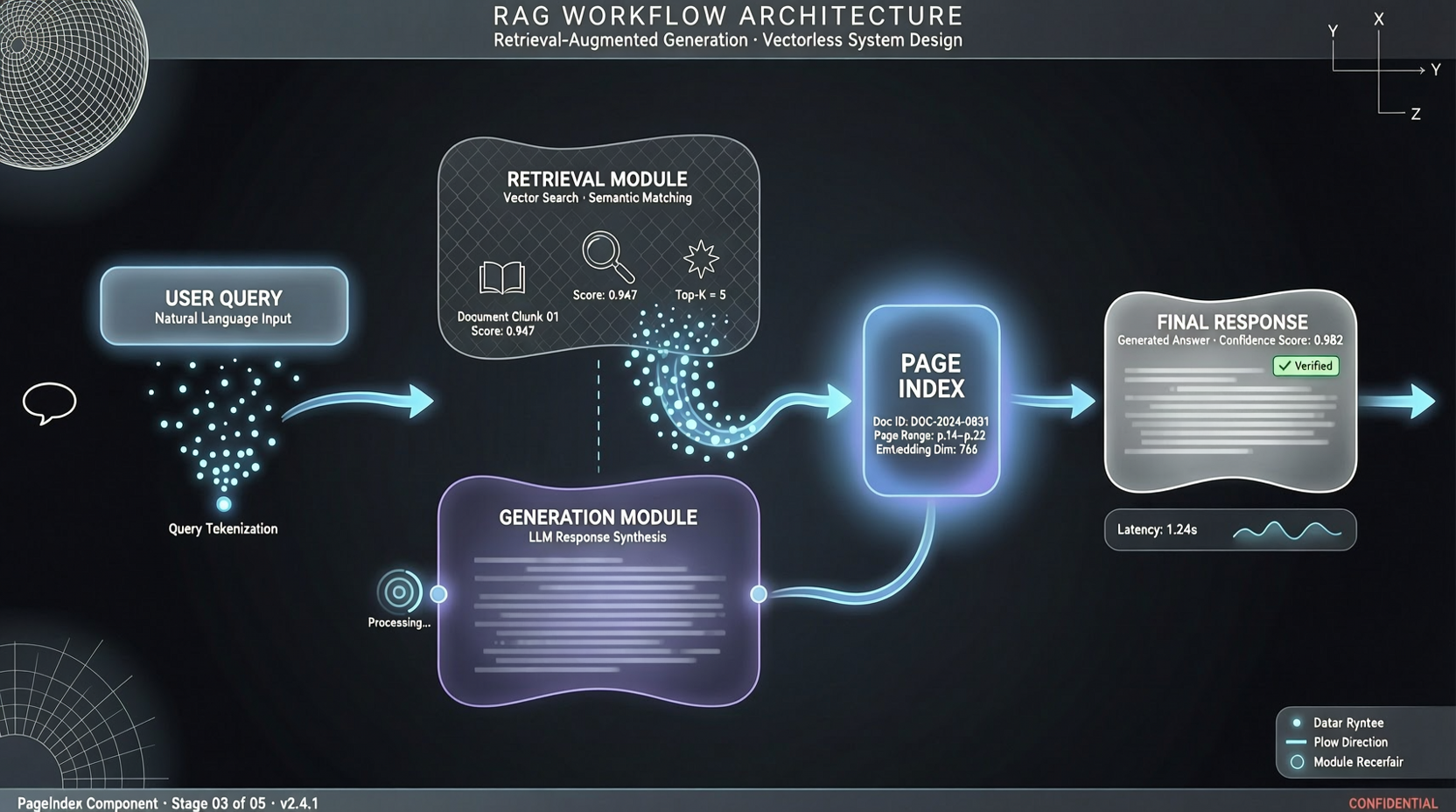
RAG(检索增强生成)用了几年了。大多数人的做法都一样:文档切片 → 向量化 → 存入向量数据库 → 查询时做语义相似度匹配 → 把最相似的片段塞给 LLM。
这套流程有个一直被吐槽的问题:向量相似度不等于信息相关性。 两个文本在向量空间里离得近,不代表它们在逻辑上有关联。
PageIndex 想换个做法。
它是什么
PageIndex 是 VectifyAI 开源的"文档索引"系统,主打无向量、基于推理的 RAG(Vectorless, Reasoning-based RAG)。
核心思路:不做向量化,而是给文档建结构化的索引。查询时,不是靠向量相似度找"最像"的片段,而是让模型推理出哪些部分应该被检索,然后按索引精准提取。
30,800 颗星,本周涨了 4,555。最近 284 次 commit,最后更新在 20 小时前。项目活跃度不错。
和传统向量 RAG 的区别
| 传统向量 RAG | PageIndex | |
|---|---|---|
| 索引方式 | 向量化 + 向量数据库 | 结构化文档索引 |
| 检索方式 | 语义相似度匹配 | 推理式检索 |
| 依赖 | 需要向量数据库(Pinecone/Milvus等) | 不需要向量数据库 |
| 精度 | 受限于向量表达能力 | 受限于模型推理能力 |
说白了:把"检索"这个环节从"匹配问题"变成了"推理问题"。
这种做法的利弊
好处:
- 不需要部署和维护向量数据库,架构简化了一大截
- 对于需要精确匹配(比如法律条款、技术文档)的场景,推理式检索可能比语义相似度更准
- 索引更新更快——改索引结构比重新向量化整个文档库要轻
代价:
- 每次检索都要调用 LLM 做推理,延迟和成本都比向量匹配高
- 如果模型推理能力不够强,检索质量会直接下降
- 大规模文档库的索引构建本身也有成本
适合谁
我判断 PageIndex 最适合这几类场景:
需要高精度检索的专业领域。 法律、医疗、技术文档——这些场景里"差之毫厘谬以千里",向量相似度可能把不相关的条款混进来,推理式检索能更精准地定位。
不想维护向量数据库的团队。 向量数据库的运维成本被低估了——分片、备份、索引更新、版本升级,每一样都不轻松。如果你的团队没有专门的 infra 人力,PageIndex 的架构更友好。
文档结构清晰的场景。 如果文档本身就是结构化的(API 文档、产品手册、规范文档),PageIndex 的结构化索引能发挥最大优势。
不适合谁
- 高并发低延迟场景。 如果你需要毫秒级响应,向量检索仍然是更好的选择。推理式检索的延迟取决于模型响应速度。
- 超大规模非结构化文档。 对于海量非结构化文本(比如整个互联网的爬虫数据),向量化的规模化能力仍然更强。
我的判断
PageIndex 不是要"取代"向量 RAG,而是提供了一条替代路径。
2025 年 RAG 的关键词是"向量数据库"。2026 年可能会变成"检索策略的多元化"。向量 RAG 适合大规模、低成本、可接受一定误差的场景。PageIndex 适合小规模、高精度、愿意为准确度支付额外成本(推理时间和 API 费用)的场景。
如果你现在的向量 RAG 效果不理想,尤其是经常检索出不相关的内容,PageIndex 值得试一下。但如果你目前的向量 RAG 跑得挺好,没必要为了追新而迁移——工具是为你服务的,不是让你为它服务的。
主要来源:
- GitHub - VectifyAI/PageIndex(仓库分析)
- GitHub Trending Weekly(热度追踪)
- 传统向量 RAG 架构对比