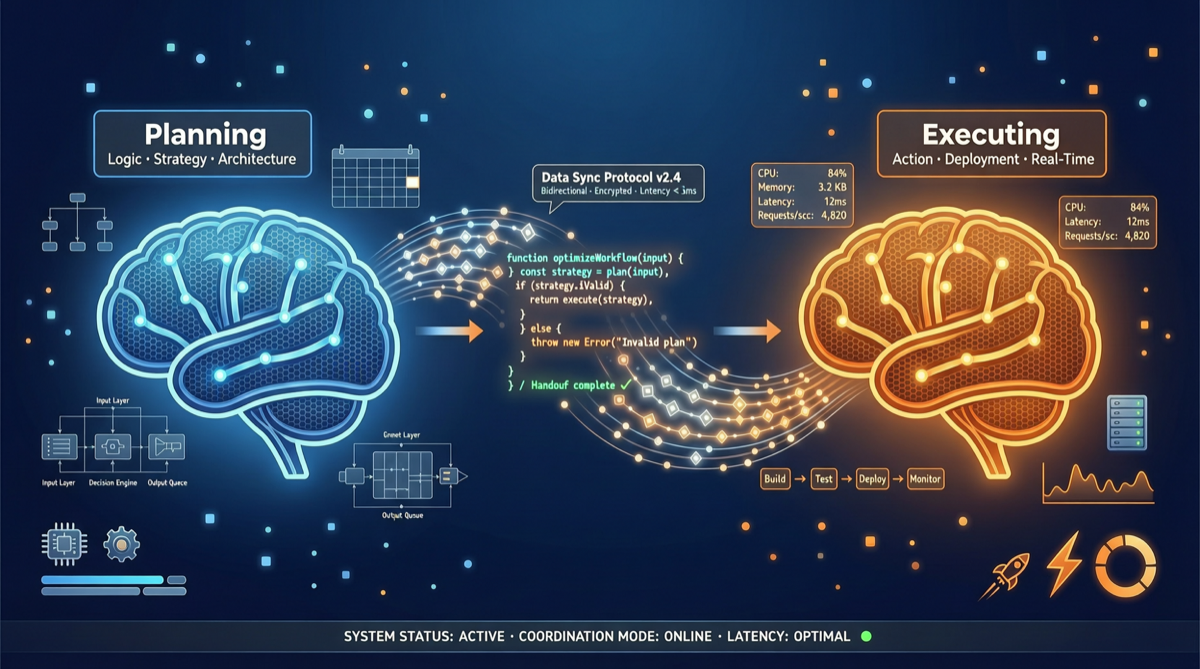
核心结论
社区实测验证了一个反直觉的发现:最好的 AI 编码工作流不是用最强的单个模型,而是让两个模型"对抗协作"——Claude Opus 4.7 负责架构规划与代码审查,GPT-5.5 负责代码生成与执行。这种分工在编码质量上"不是接近,而是碾压"单模型方案。
为什么双模型有效
单模型方案的根本问题是"能力耦合"——同一个模型既要理解需求、又要规划架构、又要写代码、还要自我审查。这导致:
- 上下文污染:规划和执行混在一起,关键决策被细节淹没
- 自我审查失效:模型很难发现自己的系统性错误
- 风格不一致:不同任务的最优提示策略冲突
双模型方案通过"角色分离"解决这些问题:
| 角色 | 模型 | 优势 |
|---|---|---|
| 规划者 | Claude Opus 4.7 | 深度推理、架构思维、安全审查 |
| 执行者 | GPT-5.5 | 代码生成速度、API 熟练度、Terminal-Bench 表现 |
工作流设计
需求输入
↓
[Opus 4.7] 架构规划
├── 模块分解
├── 接口设计
├── 技术选型
└── 风险评估
↓
[GPT-5.5] 代码执行
├── 按模块生成代码
├── 编写测试用例
└── 修复编译错误
↓
[Opus 4.7] 代码审查
├── 架构一致性检查
├── 安全隐患扫描
└── 优化建议
↓
[GPT-5.5] 迭代修复
↓
最终输出
提示词模板(精简版)
规划者(Opus 4.7):
你是一个资深软件架构师。请根据以下需求,输出:
1. 模块分解(不超过 5 个模块)
2. 每个模块的接口定义
3. 技术选型建议及理由
4. 潜在风险点
需求:[用户输入]
执行者(GPT-5.5):
你是一个高级开发工程师。请严格按照以下架构规范实现代码:
架构文档:[Opus 输出的规划]
要求:
- 只生成指定模块的代码
- 包含完整的类型定义
- 为每个函数编写 docstring
审查者(Opus 4.7):
请审查以下代码实现是否符合原始架构规划:
1. 是否存在架构偏离
2. 是否有安全隐患
3. 代码质量评分(1-10)
架构规划:[原始规划]
代码实现:[GPT 输出的代码]
成本分析
| 方案 | 单次任务成本(估算) | 质量 |
|---|---|---|
| 仅 Opus 4.7 | $0.80 | 高 |
| 仅 GPT-5.5 | $0.30 | 中 |
| 双模型工作流 | $0.60 | 最高 |
双模型方案的成本介于两者之间,但质量最优。关键是规划者和审查者的 token 消耗远低于执行者——Opus 的输出是结构化的规划文档,而非完整代码。
与现有方案的对比
| 方案 | 优势 | 劣势 |
|---|---|---|
| 单模型(Opus/GPT) | 简单、低成本 | 质量天花板低 |
| 多模型并行路由 | 自动选择最优模型 | 仍是单轮调用 |
| 双模型对抗协作 | 质量最高 | 需要编排基础设施 |
| Agent Harness(jcode 等) | 自动化程度高 | 配置复杂 |
何时使用双模型工作流
推荐使用:
- 复杂项目架构设计
- 需要高可靠性的生产代码
- 安全敏感的模块(认证、支付等)
- 代码审查与重构
不推荐使用:
- 简单的脚本编写
- 原型开发(速度优先)
- 预算极其有限的场景
自动化路径
手动编排双模型工作流可行但繁琐。自动化方向包括:
- jcode / Agent Harness:已有项目支持多模型编排,可直接配置
- n8n 工作流:通过 MCP 连接 Claude 和 OpenAI API,构建自动化 pipeline
- 自定义脚本:用 Python 脚本串联两个 API 调用,成本最低
行业信号
这个工作流的流行反映了一个更大的趋势:2026 年的 AI 编程竞争已经从"哪个模型最强"转向"如何编排多个模型"。
正如社区声音所言:"Model Quality 正在成为商品化话题。真正的护城河在于 Agentic 工作流、工具使用的信任评估、以及模型切换的速度。"
双模型对抗编程就是这个趋势的早期实践——它不追求单一模型的完美,而是通过系统设计让现有模型发挥最大价值。