痛点
当前的多模态 AI 系统普遍面临一个架构困境:
多模态理解:LLM + Vision Encoder → 文本输出
图像生成:扩散模型 / DiT → 图像输出两套架构、两套推理流程、两套 API。当你想构建一个”能看图、能思考、能画图”的 Agent 时,需要拼凑至少三个组件。
方案
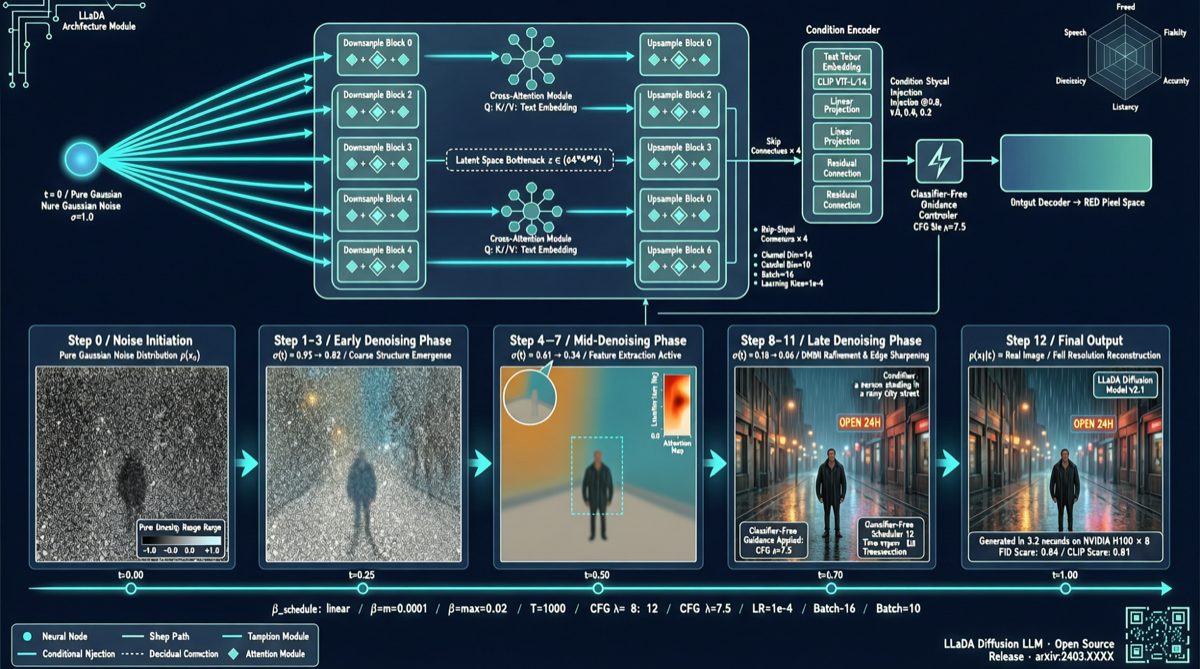
LLaDA2.0-Uni 来自 Inclusion AI,它用一条不同的技术路线解决了这个问题:用扩散 LLM 统一一切。
核心架构
| 组件 | 技术方案 | 作用 |
|---|---|---|
| 骨干网络 | MoE (Mixture of Experts) | 高效推理,灵活扩展 |
| 图像 Tokenizer | SigLIP-VQ | 图像离散化,支持理解与生成 |
| 推理方式 | 离散扩散过程 | 统一的理解+生成机制 |
| 上下文处理 | 原生交错序列 | 文本和图像 token 自然混合 |
关键特性
-
8 步图像生成
- 传统扩散模型需要 50-100 步
- LLaDA2.0-Uni 仅需 8 步即可出图
- 推理速度提升 6-12 倍
-
原生交错推理
- 文本 token 和图像 token 可以在同一个序列中自由混合
- “看图 → 思考 → 画图” 在单一推理过程中完成
- 不需要切换模型或 API
-
统一的理解与生成
- 同一个模型既做多模态理解(读图+回答),也做图像生成
- 不再需要”理解模型”和”生成模型”两套系统
与同期方案的对比
| 维度 | LLaDA2.0-Uni | Meta Tuna-2 | SenseNova U1 | GPT-4o |
|---|---|---|---|---|
| 架构 | 扩散 LLM + MoE | 无编码器+像素嵌入 | 单体多模态 | LLM+多模态 |
| 图像生成 | ✅ 8 步扩散 | ✅ | ✅ | ❌ 需 DALL-E |
| 图像理解 | ✅ | ✅ | ✅ | ✅ |
| 交错推理 | ✅ 原生 | 部分 | ✅ | 部分 |
| 开源 | ✅ | ✅ | ✅ | ❌ |
| 生成速度 | 8 步 | 取决于架构 | 取决于架构 | N/A |
扩散 LLM vs 传统扩散模型
LLaDA2.0-Uni 的扩散机制与 Stable Diffusion 等传统扩散模型有本质区别:
- 传统扩散:在连续像素空间操作,每步去噪
- 扩散 LLM:在离散 token 空间操作,每步”去噪”token 序列
- 优势:与 LLM 推理天然兼容,可以复用 LLM 的所有工具(上下文学习、思维链、tool calling)
上手指南
部署路径
- 获取模型:Hugging Face 已发布开源权重
- 推理框架:需要支持扩散 LLM 的推理后端
- 硬件需求:MoE 架构的实际显存取决于激活参数量
- API 兼容:可通过 OpenAI 兼容接口接入 Agent 框架
典型应用场景
| 场景 | 为什么适合 |
|---|---|
| 多模态 Agent | 单一模型搞定理解+生成,架构简单 |
| 交互式图像编辑 | ”把图中这个改成那样”——理解和生成在同一上下文 |
| 数据增强 | 理解已有数据分布,生成新样本 |
| 视觉推理 | 看图→推理→可视化输出,一条流水线 |
格局判断
扩散 LLM 代表了多模态 AI 的另一条技术路线,与 Meta Tuna-2 的像素嵌入路线、SenseNova U1 的单体架构形成互补:
- LLaDA2.0-Uni(扩散路线):擅长生成交互、交错推理,与 LLM 生态兼容性好
- Tuna-2(像素嵌入路线):擅长细粒度感知,视觉精度高
- SenseNova U1(单体路线):架构简单,推理效率高
短期内,三条路线各有优势场景。中长期看,如果扩散 LLM 能在生成质量和速度上持续突破,它可能成为多模态 Agent 的首选基础模型。