科研能不能"睡一觉醒来就跑完了"?
上交大团队在 arXiv:2605.03042 发布了 ARIS(Auto-Research-in-sleep),一个开源的自主科研框架。一周不到,GitHub 已经 8.9k star。
这不是又一个"AI 帮你查文献"的工具。ARIS 的核心设计是对抗式多 Agent 协作:一个执行模型负责推进研究,一个不同模型家族的审稿模型负责挑刺。不是合作,是博弈。
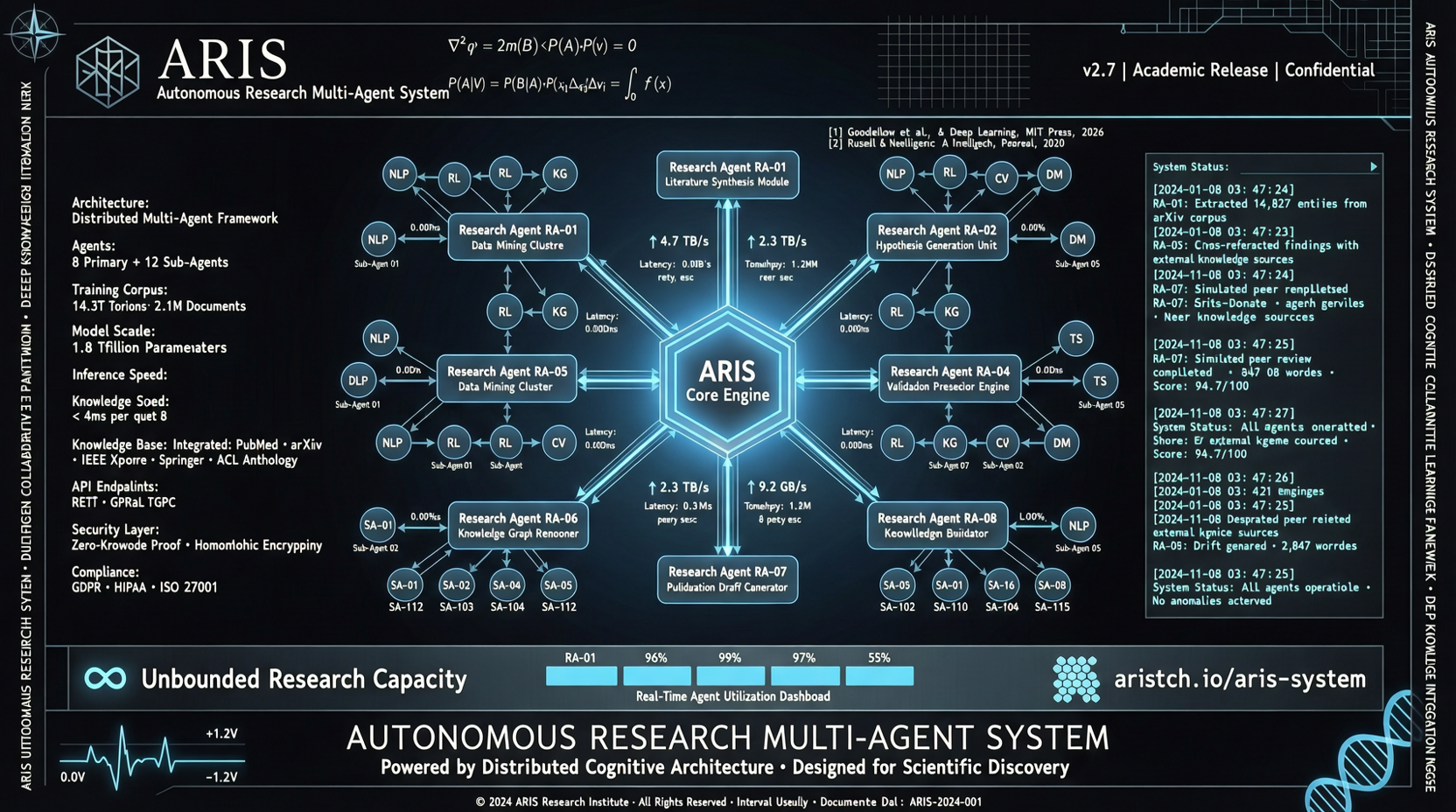
架构拆解:三层结构
ARIS 分三层,每层解决不同的问题。
执行层。 65 个以上用 Markdown 定义的可复用技能,通过 MCP 接入不同模型,还有个持久化的研究 wiki 用于积累已有发现。最关键的是确定性图表生成——科研论文里图表的随机性是致命伤,ARIS 解决了这个。
编排层。 五个端到端工作流,可以调 effort 参数控制投入,还能配置路由到不同的审稿模型。你可以让 GPT 系列做执行,Claude 系列做审稿,反之亦然。
保障层。 这才是 ARIS 最硬的部分。三阶段证据验证流程:完整性检查→结果到主张的映射→主张审计。简单说就是确保论文里写的每一句话,都能在原始实验数据里找到支撑。外加五轮科学编辑流水线、数学证明检查和 PDF 渲染视觉检查。
为什么要用"对抗"而不是"协作"
论文里有一句话很关键:
"对于长周期科研工作流,核心失败模式不是明显的崩溃,而是一个看起来合理但缺乏证据支撑的成功。"
一个长时间运行的 Agent 可以生成看起来很对的结论,但这些结论的证据链可能是断裂的、被曲解的,或者从执行者的预设立场中隐性继承的。
对抗式设计的价值就在于此:审稿模型和执行模型来自不同的模型家族,它们有不同的训练数据和行为偏好。执行模型说"这个实验结果支持结论 A",审稿模型的任务就是找出"这个结论其实不成立"的证据。
自改进闭环
ARIS 还有个 prototype 级别的 self-improvement loop:记录研究 trace,提出 harness 改进建议,但只有审稿模型批准后才采纳。
这个设计很克制。不是所有改进都值得接受,让"对手"来当 gatekeeper,比让作者自己决定要靠谱得多。
实际能用吗
论文提到的是"early deployment experience",说明已经在实际跑了。但具体产出了什么论文、质量如何,目前还没有公开的同行评审结果。
从技术成熟度看,ARIS 的架构完整度相当高。65+ 技能、三阶段验证、五轮编辑——这不是一个概念验证,而是一个工程化的系统。
但科研这事,最终还是要看产出质量。如果 ARIS 能产出一篇通过同行评审的论文,那才是真正的里程碑。
跟谁比
之前的自主科研方向有几个工作:
- Sakana AI 的 AI Scientist(2024 年 8 月)——用 LLM 生成 ML 论文,但缺乏严格的证据验证
- ChemCrow 等化学领域 Agent——限定在特定学科
- OpenHands 等通用 coding Agent——可以做实验但不涉及科研流程
ARIS 的定位更偏向"科研基础设施",不绑死某个领域,而是提供一套可复用的科研 harness。
主要来源:
- arXiv:2605.03042 - ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
- GitHub: github.com/wanshuiyin/Auto-claude-code-research-in-sleep