用 Claude Code 的时候,每次问它"这个项目里 X 功能是怎么实现的",它都要先跑一堆 grep、read、ls 来熟悉代码结构。每跑一次工具调用,token 就上去了。
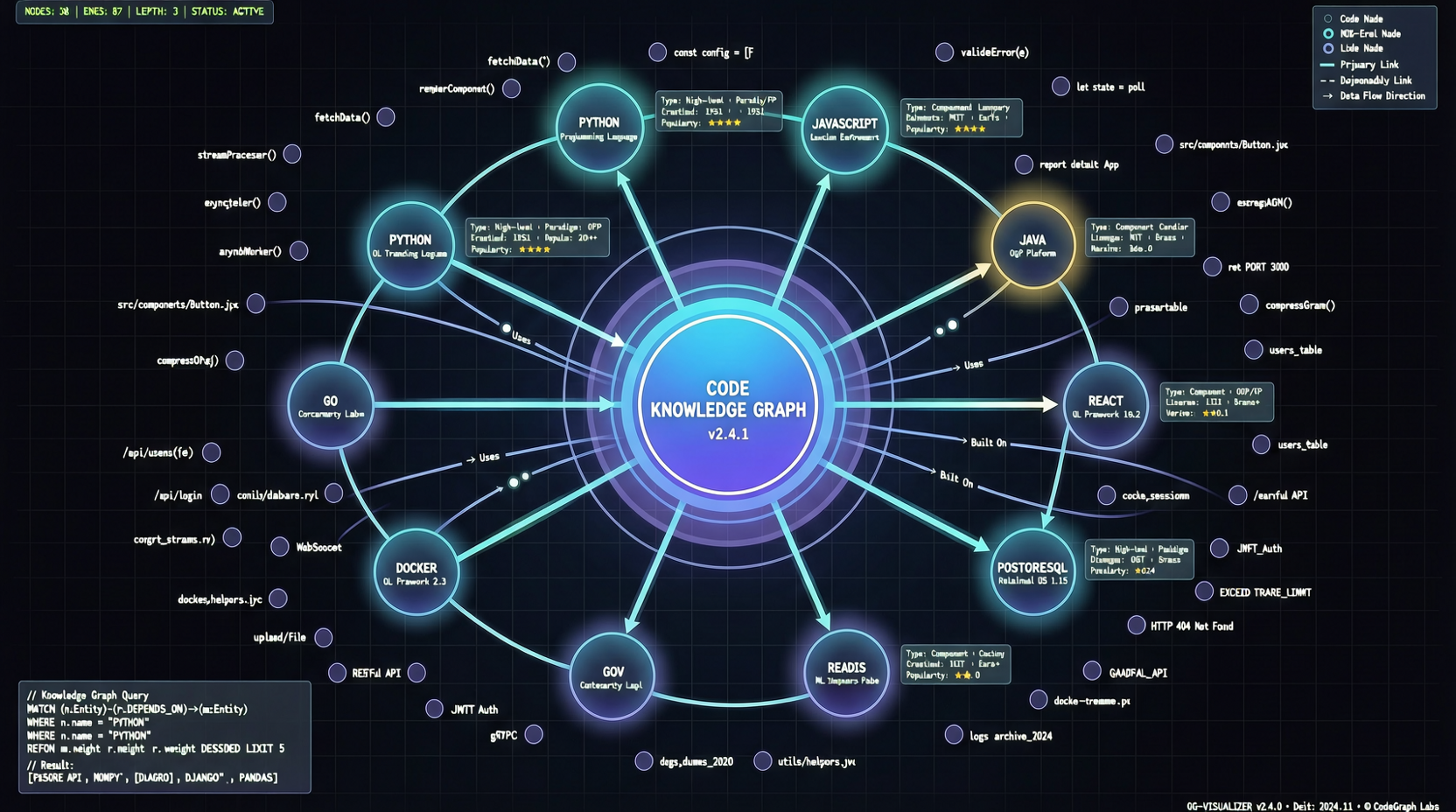
codegraph 的想法很直接:先把代码结构预索引成知识图谱,Agent 问问题的时候直接从图谱里查,而不是临时扫描文件。
项目上线后 GitHub 一周涨了 4600+ star,目前 6.9k。最新提交是 43 分钟前——作者基本住在 repo 里了。
为什么这玩意儿有用
编程 Agent 在陌生项目上最大的开销不是"推理",而是"探索"。它不知道哪个文件包含什么,只能一个一个读。一个中等规模的项目,Agent 第一次对话可能要读几十个文件,token 消耗轻松破万。
codegraph 把这个过程前置了。它预先扫描整个代码库,构建出文件、类、函数之间的依赖关系图谱。Agent 提问时,不需要读文件,直接从图谱里查到"X 函数在文件 A 的第 N 行,被 B、C 两个文件调用"。
作者的说法是:更少的 token、更少的工具调用、100% 本地运行。
兼容性和生态
这可能是这个项目最聪明的地方。它不绑定任何一个 Agent 平台:
- Claude Code
- OpenAI Codex
- Cursor
- OpenCode
通过 MCP(Model Context Protocol)提供标准化接口。只要你的 Agent 支持 MCP,就能接入。
它还自带 .cursor/rules 目录,说明作者考虑到了 Cursor 用户的规则配置需求。
架构
TypeScript 写的,275 个 commit,最新版本 0.7.12。更新频率高到离谱。
核心流程分两步:
- 索引阶段:扫描项目,提取文件结构、函数签名、依赖关系,存入本地图谱数据库
- 查询阶段:Agent 通过 MCP 协议查询图谱,获取结构化信息而非原始代码
这个设计的优势在于索引只需要做一次(或者在代码大幅变动时重建),之后的所有查询都是 O(1) 级别的关系查找,而不是 O(n) 的文件扫描。
适用边界
不是所有项目都需要。如果你的项目只有几十个文件,Claude Code 自带的探索能力足够了。codegraph 的价值在中大型项目上更明显——几百个文件、多层目录、复杂依赖关系。
另外,它解决的是"理解项目结构"的问题,不是"理解代码逻辑"的问题。图谱告诉你"谁调用了谁",但不告诉你"这段代码在做什么"。两者互补,不是替代。
我怎么看
这类工具的涌现说明了一个趋势:Agent 工作流正在从"无状态 + 全量探索"向"有状态 + 预索引"转变。就像数据库从全表扫描演进到建索引,是一个必然方向。
项目还很早期,22 个 open issue,36 个 PR。但更新速度和社区热情都很强,值得持续关注。如果你在用 Claude Code 处理大项目,花十分钟装一个试试,token 账单可能会有惊喜。
主要来源:
- codegraph GitHub
- GitHub Trending(本周 TypeScript 类目)