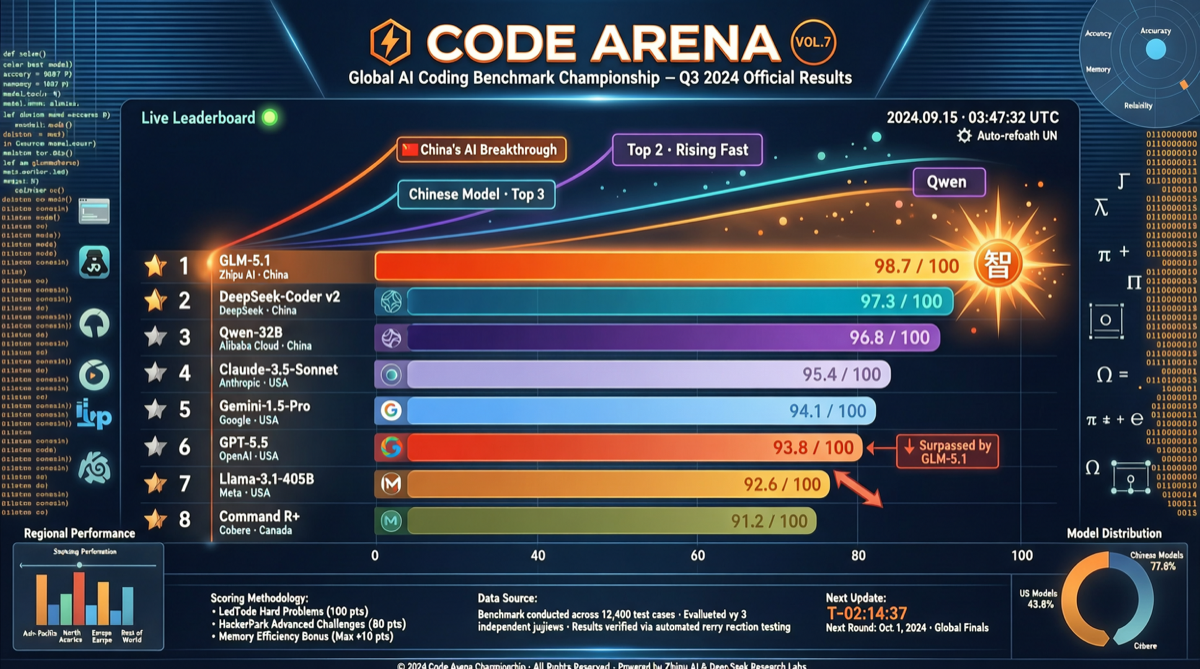
核心数据
Code Arena 最新一期排名出炉,编码领域格局发生显著变化。在 46 个参评的 agentic coding 模型中,国产模型占据了最引人注目的位置:
| 排名 | 模型 | Code Arena 评分 |
|---|---|---|
| 1 | GLM-5.1 | ~1535+ |
| 2 | Kimi K2.6 | ~1520+ |
| 3 | MiMo-V2.5-Pro | ~1510+ |
| … | … | … |
| 5 | GLM-5.1(确认位次) | 1535 |
| 9 | GPT-5.5 High | 1500 |
关键事实:GLM-5.1 在 Code Arena 中的评分(1535)已明确超越 GPT-5.5 High(1500),在 agentic coding 和 web dev 任务上表现尤为突出。
国产编码三强格局
结合多个维度的数据,国产模型在编码领域已形成”三强+追赶者”格局:
GLM-5.1:智谱最新模型,在 Code Arena 中表现抢眼。此前智谱公开发布了 GLM-5 训练过程中遇到的 Scaling Pain 复盘 blog,坦诚公开了模型输出乱码、复读、生僻字等问题的调试过程——这种透明态度在业界罕见。GLM-5.1 正是经过这些问题修复后的版本,编码能力大幅提升。
Kimi K2.6:月之暗面的旗舰模型,在 SWE-Bench Pro 上以 58.6 分登顶开源模型,超越 GPT-5.4 和 Claude 4.6。K2.6 采用 Agent Swarm 架构,支持 300 个并行子 Agent、4000 步深度推理,重新定义了 Agent 规模的天花板。
MiMo-V2.5-Pro:小米大模型团队负责人罗福莉主导研发的模型。在最近 3.5 小时的深度专访中,罗福莉透露了小米在 Pre-train 代差消失后的技术路线选择——转向 Agent RL 方向。MiMo 的快速上位印证了这一路线的有效性。
意外落榜者:DeepSeek V4 Pro
最具戏剧性的是 DeepSeek V4 Pro 的表现。作为一度被视为国产模型王者的存在,V4 Pro 在此次编码排名中意外垫底。这可能反映了几个趋势:
- V4 Pro 的优化方向偏重通用推理,在 agentic coding 的专项场景中不占优势
- 竞品迭代速度加快,GLM-5.1、K2.6 的编码专项优化效果显著
- DeepSeek 的 API 缓存降价策略虽降低了使用成本,但并未转化为编码能力的提升
行业意义
这次排名变化传递了几个重要信号:
- 国产模型在编码领域已不再追赶,GLM-5.1 超越 GPT-5.5 High 是标志性事件
- 透明复盘文化正在形成:智谱公开 Scaling Pain、Anthropic 公开质量下降复盘、OpenAI 公开”Goblin”输出事件复盘——大模型公司的工程透明度在提升
- Agent 架构成为分水岭:K2.6 的 300 并行子 Agent、GLM-5.1 的 self-evaluation(构建完整 Three.js 赛车游戏进行自我评估),表明 Agent 原生架构正在取代单纯的模型规模竞赛
对于开发者和企业来说,这意味着在 agentic coding 场景下,国产模型已经从”可用”走向”好用”,甚至在某些场景下成为首选。