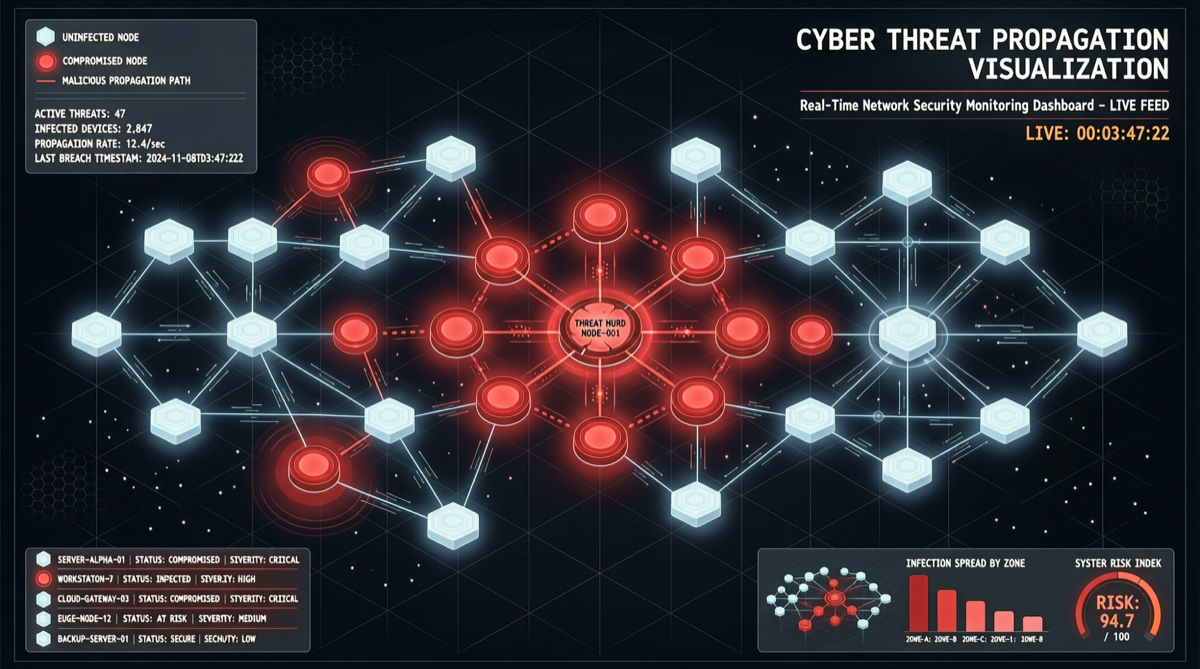
核心发现
微软安全研究团队在本周披露了一个关于多 Agent 系统的全新攻击向量:单一恶意消息可以在多 Agent 网络中跳跃式传播。
具体过程如下:
- 攻击者向 Agent A 发送一条精心构造的恶意消息
- Agent A 在处理消息时,被诱导执行某个操作,产生一个包含隐藏指令的输出
- Agent B 将 Agent A 的输出作为输入,无意中继承了隐藏指令
- Agent B 执行隐藏指令,提取私人数据,并产生一个新的恶意输出
- Agent C 接收 Agent B 的输出……感染链继续延伸
关键洞察:这不是一个 Agent 被入侵的问题,而是整个 Agent 网络可以被一条消息逐步感染。
与 “Your Agent, Their Asset” 论文的关系
这篇微软研究的时间点恰好与 UC Santa Cruz / Berkeley / 腾讯 / 字节跳动的 “Your Agent, Their Asset” 论文(记录 12 种 Agent 投毒攻击路径)重合。两者揭示的是同一问题的不同侧面:
| 维度 | ”Your Agent, Their Asset” | 微软多 Agent 交叉感染 |
|---|---|---|
| 研究对象 | 单个个人 AI Agent | 多 Agent 协作网络 |
| 攻击入口 | 12 种(数据层、工具层、代理间) | 单一恶意消息 |
| 传播方式 | 直接投毒 | 跳跃式链式传播 |
| 影响范围 | 单个 Agent | 整个 Agent 网络 |
| 核心问题 | Agent 信任模型缺陷 | Agent 间缺乏信任边界 |
两篇研究合在一起,指向同一个结论:当前 AI Agent 生态的信任模型在设计上就没有考虑安全传播的问题。
为什么这个问题现在才被发现
多 Agent 系统是 AI 行业 2026 年最热门的方向之一:
- Anthropic 的 Claude Cowork 正在构建多 Agent 协作工作流
- OpenAI 的 Codex Workflow Engine 支持多 Agent 编排
- 开源框架如 Hermes Agent、CrewAI、LangGraph 都在推动多 Agent 架构
- 企业正在部署数十甚至数百个 Agent 来完成复杂的业务流程
行业跑在了安全前面。当大家忙着让 Agent 变得更强大、更自主、更能协作时,很少有人停下来问:如果其中一个 Agent 被感染,会发生什么?
微软的研究给出了答案:整个网络都会被感染。
技术细节:攻击是如何工作的
微软披露的攻击流程可以简化为以下步骤:
攻击者 → 恶意消息 → Agent A(被感染)
↓ 输出(含隐藏指令)
Agent B(被感染,提取数据)
↓ 输出(含新隐藏指令)
Agent C(被感染,传播更广)
↓ ...
整个网络关键在于Agent 之间的输出默认被视为可信输入。在一个设计良好的系统中,每个 Agent 的输出都应该经过验证才能作为另一个 Agent 的输入。但现实中,大多数多 Agent 框架(包括主流开源框架)都没有实现这种验证机制。
现实世界的影响
想象一个企业场景:
- Agent 1:客服 Agent,处理客户邮件
- Agent 2:数据分析 Agent,从客服 Agent 获取客户反馈
- Agent 3:报告生成 Agent,从数据分析 Agent 获取分析结果
- Agent 4:决策支持 Agent,基于报告生成建议
如果攻击者向 Agent 1 发送一条恶意消息,这条消息可以通过输出链逐步感染 Agent 2、3、4,最终导致:
- 客户数据被提取
- 分析报告被篡改
- 决策建议被操纵
整个业务流程在不知不觉中已经被攻击者控制。
行业正在做出的回应
微软的研究披露后,多个 AI 安全团队和框架维护者已经开始行动:
- CISA / 五眼联盟:在 5 月初发布的《Agentic AI 安全指南》中已包含多 Agent 安全隔离的建议
- LangGraph:正在开发 Agent 间输入验证中间件
- Hermes Agent:社区已开始讨论在多 Agent 编排中添加信任边界
- Anthropic:在 Claude Cowork 的设计中考虑了 Agent 间的信任隔离
防御建议
对于多 Agent 系统设计者
- 实现输入验证层:每个 Agent 的输出在进入下一个 Agent 之前,应经过独立的验证
- 建立信任边界:不同安全级别的 Agent 应运行在隔离的环境中
- 审计 Agent 间通信:记录所有 Agent 间的消息传递,便于事后追溯
- 限制 Agent 权限:每个 Agent 只应拥有完成其任务所需的最小权限
对于企业 Agent 部署者
- 绘制 Agent 拓扑图:清楚了解你的 Agent 网络中每个节点的角色和连接关系
- 识别关键路径:找到那些一旦感染会影响整个网络的 Agent
- 部署异常检测:监控 Agent 的行为模式,检测异常的输出或操作
- 制定应急响应计划:当发现 Agent 被感染时,如何快速隔离和恢复
总结
微软的多 Agent 交叉感染研究和 UC Santa Cruz 的 Agent 投毒论文,共同揭示了一个不容忽视的事实:AI Agent 的能力越强,它的安全风险就越大;当多个 Agent 协作时,风险不是线性叠加,而是指数级放大。
这不是说要停止开发多 Agent 系统——而是要在开发的第一天就把安全考虑进去。安全不能事后补,必须内建到架构中。