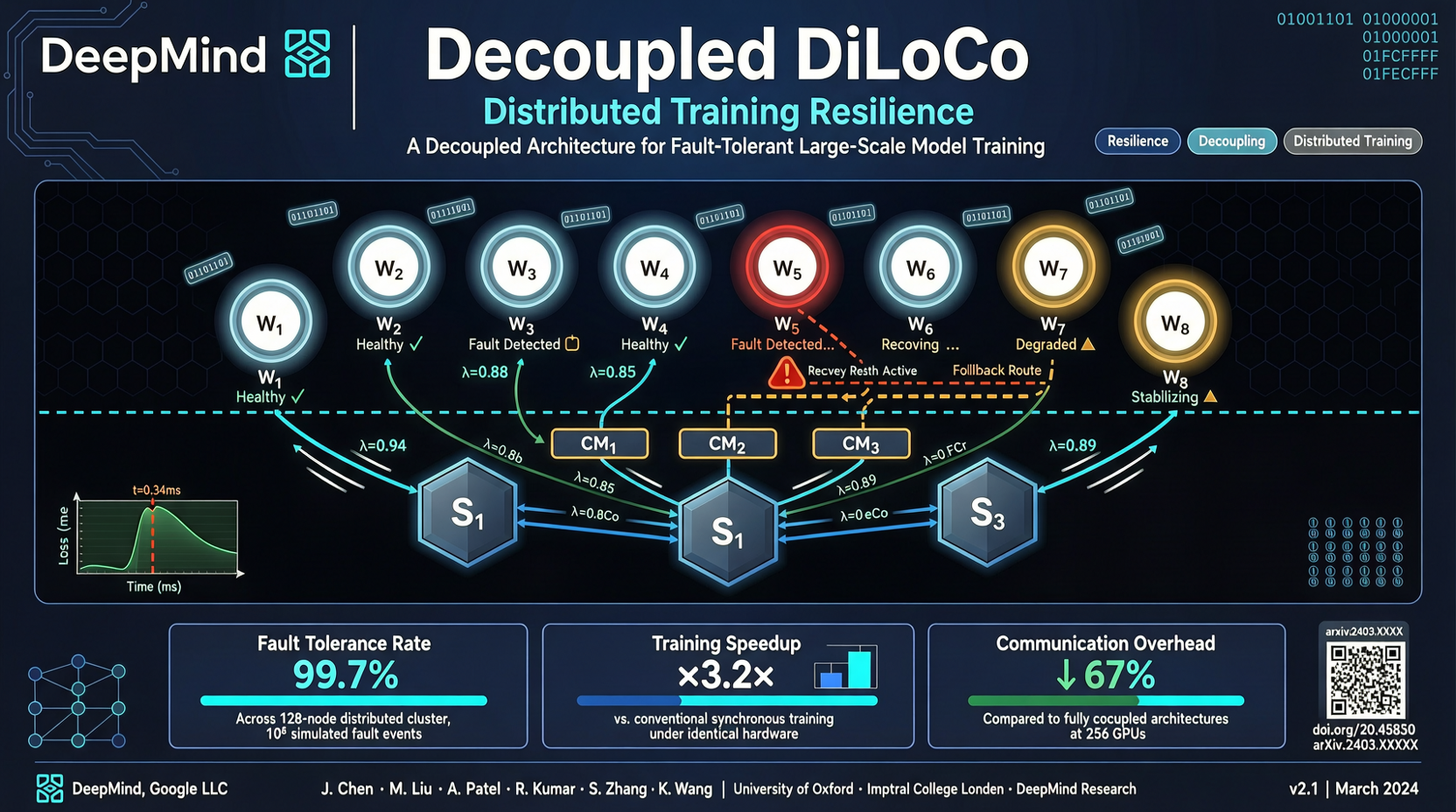
The most expensive part of training a frontier model isn't compute itself — it's the constraint that "compute can't be wasted."
When training on 10,000 GPUs, one failed card can force a rollback of the entire cluster. Decoupled DiLoCo decouples local optimization from global synchronization so that one node failing doesn't drag down the rest.
Author list includes Jeff Dean and Marc'Aurelio Ranzato — this isn't an academic toy, it's a production-scale solution.
Main sources: