训练一个前沿大模型最贵的不是算力本身,是"算力不能浪费"这个约束带来的隐性成本。
当你用 10,000 张 GPU 做分布式训练时,只要有一张卡出问题,整个集群可能就要回滚。回滚意味着之前跑的计算全部白费——按目前的 GPU 租赁价格,一次回滚可能就是几万到几十万美元的损失。
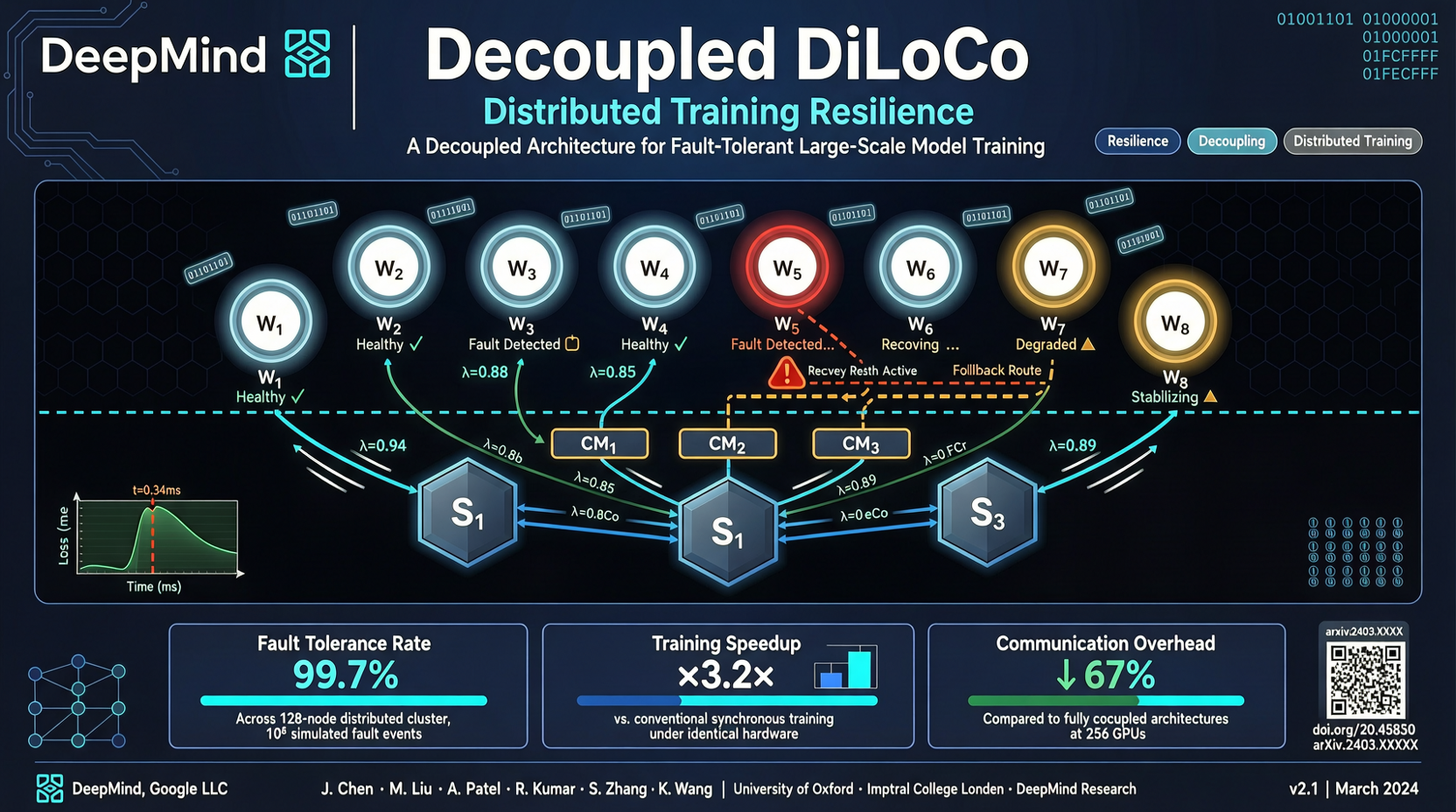
Google DeepMind 在 4 月底发表的 Decoupled DiLoCo 论文,解决的就是这个问题。
DiLoCo 是什么
DiLoCo(Distributed Low-Communication Training)的核心思路是:把分布式训练中的同步频率降下来。传统的分布式训练需要所有节点频繁地交换梯度信息,通信成本很高。DiLoCo 让各个节点在本地跑更多步再同步,减少了通信量。
但原版 DiLoCo 有个问题:它假设所有节点都能稳定运行。一旦有节点掉线,同步机制就会出问题。
Decoupled DiLoCo 的改进就在于"解耦"——把本地优化和全局同步解耦开来。每个节点独立维护自己的优化状态,即使其他节点出问题,也不会把自己的进度拖下水。
这个改进有多重要
论文的作者阵容本身就说明问题:Jeff Dean、Marc'Aurelio Ranzato、Arthur Douillard、Josef Dean——Google DeepMind 的核心研究力量。这不是一个学术玩具,是一个面向实际大规模训练的方案。
从工程角度看,它的价值可以用一个简单的公式理解:
训练成本 = GPU 小时数 × 单价 × (1 + 回滚损失率)
回滚损失率是目前大模型训练中最大的不确定变量之一。在万卡级别,这个比率可能达到 5%-15%。Decoupled DiLoCo 如果能把它降到 1%-3%,省下来的钱足以覆盖整个研究团队几年的工资。
和现有方案的对比
目前行业里应对节点故障的主要方案是 checkpointing——定期保存训练状态,出问题就从上一个 checkpoint 恢复。但 checkpointing 有两个问题:
第一,保存和恢复本身需要时间,在万卡集群上,一次完整的 checkpoint 可能要几分钟到十几分钟。第二,你只能恢复到 checkpoint 的时刻,checkpoint 之间的计算还是浪费了。
Decoupled DiLoCo 的思路是"不让问题发生",而不是"发生了再恢复"。各个节点之间的解耦意味着一个节点出问题不会传播到其他节点,其他节点可以继续训练。
但别急着换训练框架
论文目前只报告了实验结果,还没有大规模生产环境的数据。在几百卡的规模上有效,不代表在万卡规模上同样有效——分布式系统的行为往往不是线性放大的。
另外,Decoupled DiLoCo 对训练收敛性的影响也需要更多验证。降低同步频率和解耦优化状态,理论上可能会影响模型的最终质量。论文声称收敛质量不受影响,但这需要在多个模型架构和规模上重复验证。
一个更大的趋势
Decoupled DiLoCo 不是孤立的技术突破。它反映了一个更大的趋势:大模型训练正在从"能不能训练出来"转向"能不能高效、稳定、经济地训练出来"。
当模型能力本身已经不再是瓶颈,训练过程的效率、容错性、成本可控性开始成为决定谁能赢的因素。这就是为什么 Google DeepMind、Meta、OpenAI 都在投入大量研究资源到训练系统本身,而不是只关注模型架构。
这个方向上,未来 12 个月可能还会有更多类似的技术出现。值得持续关注。
主要来源: