Every time you open Claude Code or Codex, what's the first thing you do? Feed the project structure, coding conventions, and past pitfalls to the agent again.
Agentmemory wants to end that repetition.
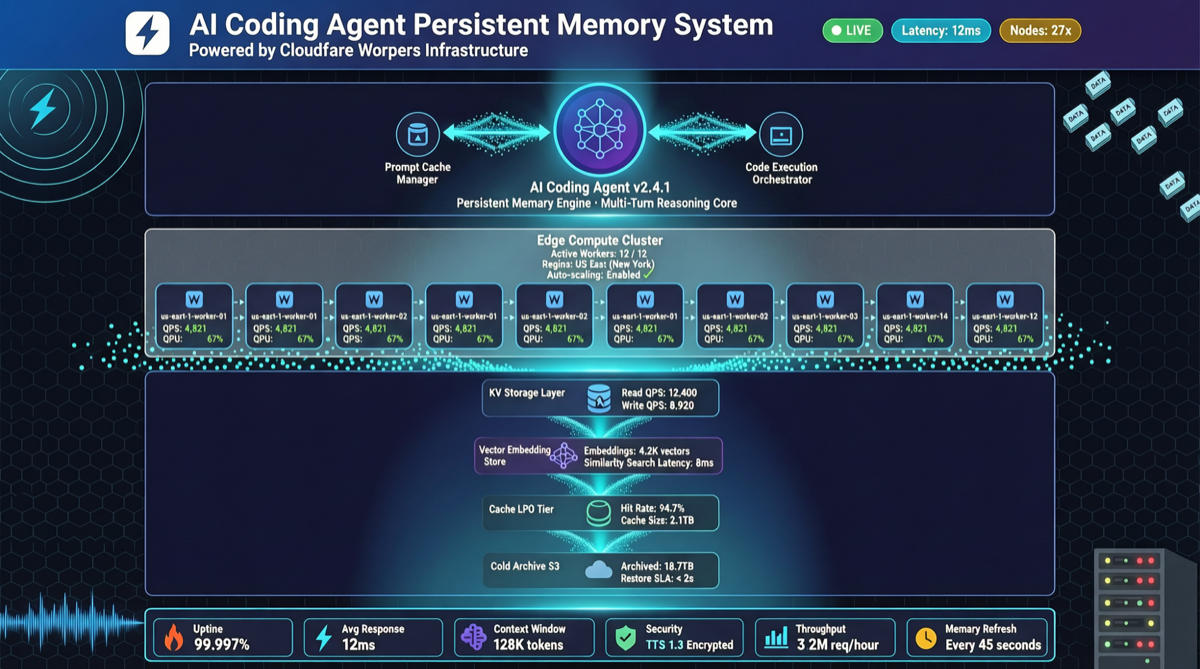
Built by rohitg00, this project adds a persistent memory layer to AI coding agents—project info, user preferences, and historical decisions are stored on Cloudflare Workers, and the agent auto-loads them on startup. Currently at 3.3k stars, up 518 yesterday alone.
What It Does
The core idea is simple: agents shouldn't start from scratch every time.
Agentmemory provides three capabilities:
- Persistent project context: Directory structure, tech stack, coding conventions are automatically recorded and restored on next agent startup
- Cross-session memory: Pitfalls the agent hit last time, architectural decisions it made—still remembered next time
- Search recall: Semantic search to retrieve relevant information from history, instead of shoving the entire context into the agent
The latest v0.9.5 adds search recall and plugin compatibility. The changelog mentions a "sandbox-model shift" in v0.9.5, suggesting underlying architecture changes.
Integration
This is Agentmemory's most competitive feature—it's not locked to a single agent. Currently supports:
- Claude Code (
.claude-plugindirectory in repo) - OpenClaw (Hermes integration fix in
integrations/directory, updated 8 hours ago) - Codex
- Any agent connecting via MCP protocol
For OpenClaw and Hermes Agent users, this means you can add a memory layer to your existing workflow without switching agents.
Architecture
Built on Cloudflare Workers, which means:
- Free tier is sufficient: Cloudflare Workers' free plan is more than enough for personal developer memory storage
- Global low latency: Memory data stored and served from edge locations
- No self-hosted database: The key difference from self-hosted vector database solutions
The repo has a benchmark/ directory, meaning the author ran performance tests. The README claims "#1 based on real-world benchmarks"—unclear how that ranking was determined, but having benchmarks is better than nothing.
Worth Installing?
If your workflow is:
Use Claude Code / Codex / OpenClaw daily for coding, project context needs to be re-fed every time
Worth installing. 5-minute setup, saves Token consumption on re-introducing project background every time. The author claims 40% Token savings—I haven't verified this number, but it makes sense in principle: memory recall is much cheaper than full context.
If your workflow is:
Occasionally use agents for small scripts, close when done
Skip it. Memory layers only add value through accumulation. Projects you use once don't need persistent memory.
Caveats
- Cloudflare Workers dependency: if Workers goes down, memory is gone. A fallback strategy would help
- Privacy concerns: project code and architectural decisions stored on third-party cloud. Enterprise users may need self-hosted deployment
- 274 commits but only 330 forks—community engagement is moderate at best
Sources: