Каждый раз, когда вы открываете Claude Code или Codex, что вы делаете в первую очередь? Снова загружаете структуру проекта, соглашения о кодировании и прошлые ошибки агенту.
Agentmemory хочет положить конец этому повторению.
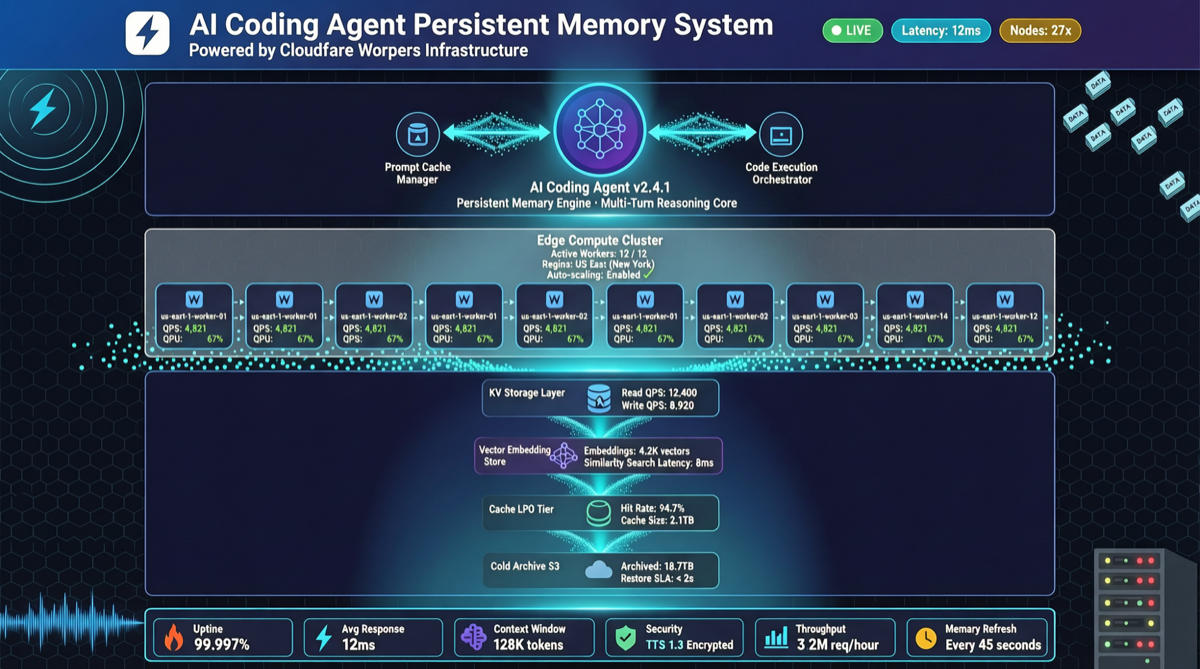
Созданный rohitg00, этот проект добавляет слой постоянной памяти для AI-агентов кодирования — информация о проекте, предпочтения пользователя и исторические решения хранятся на Cloudflare Workers, и агент автоматически загружает их при запуске. Сейчас 3.3k звёзд, +518 только за вчера.
Что он делает
Основная идея проста: агенты не должны начинать с нуля каждый раз.
Agentmemory предоставляет три возможности:
- Постоянный контекст проекта: Структура каталогов, технологический стек, соглашения о кодировании автоматически записываются и восстанавливаются при следующем запуске агента
- Память между сессиями: Ошибки, которые агент допустил в прошлый раз, архитектурные решения — всё запоминается
- Поисковый отклик: Семантический поиск для извлечения релевантной информации из истории, вместо загрузки всего контекста в агента
Последняя версия v0.9.5 добавляет поисковый отклик и совместимость с плагинами. В журнале изменений упоминается «sandbox-model shift» в v0.9.5, что указывает на изменения в базовой архитектуре.
Интеграция
Это самая конкурентоспособная особенность Agentmemory — он не привязан к одному агенту. В настоящее время поддерживает:
- Claude Code (каталог
.claude-pluginв репозитории) - OpenClaw (исправление интеграции Hermes в каталоге
integrations/, обновлено 8 часов назад) - Codex
- Любой агент, подключающийся через протокол MCP
Для пользователей OpenClaw и Hermes Agent это означает, что вы можете добавить слой памяти в свой существующий рабочий процесс без смены агента.
Архитектура
Построен на Cloudflare Workers, что означает:
- Бесплатного тарифа достаточно: Бесплатный план Cloudflare Workers более чем достаточен для хранения памяти личного разработчика
- Глобальная низкая задержка: Данные памяти хранятся и обслуживаются с граничных локаций
- Не нужно самостоятельно хостить базу данных: Главное отличие от решений с самостоятельной векторной базой данных
В репозитории есть каталог benchmark/, что означает, что автор провёл тесты производительности.
Стоит ли устанавливать?
Если ваш рабочий процесс такой:
Используете Claude Code / Codex / OpenClaw ежедневно для кодирования, контекст проекта нужно загружать каждый раз заново
Стоит установить. Настройка за 5 минут, экономия потребления токенов на повторном представлении проекта. Автор утверждает 40% экономии токенов — я не проверял это число, но в принципе это логично: отклик памяти намного дешевле полного контекста.
Оговорки
- Зависимость от Cloudflare Workers: если Workers отключится, память пропадёт
- Вопросы конфиденциальности: код проекта и архитектурные решения хранятся в стороннем облаке
- 274 коммита, но только 330 форков — вовлечённость сообщества умеренная
Источники: