每次打开 Claude Code 或者 Codex,第一件事是什么?把项目结构、编码规范、之前踩过的坑再给 Agent 讲一遍。
Agentmemory 想终结这个重复劳动。
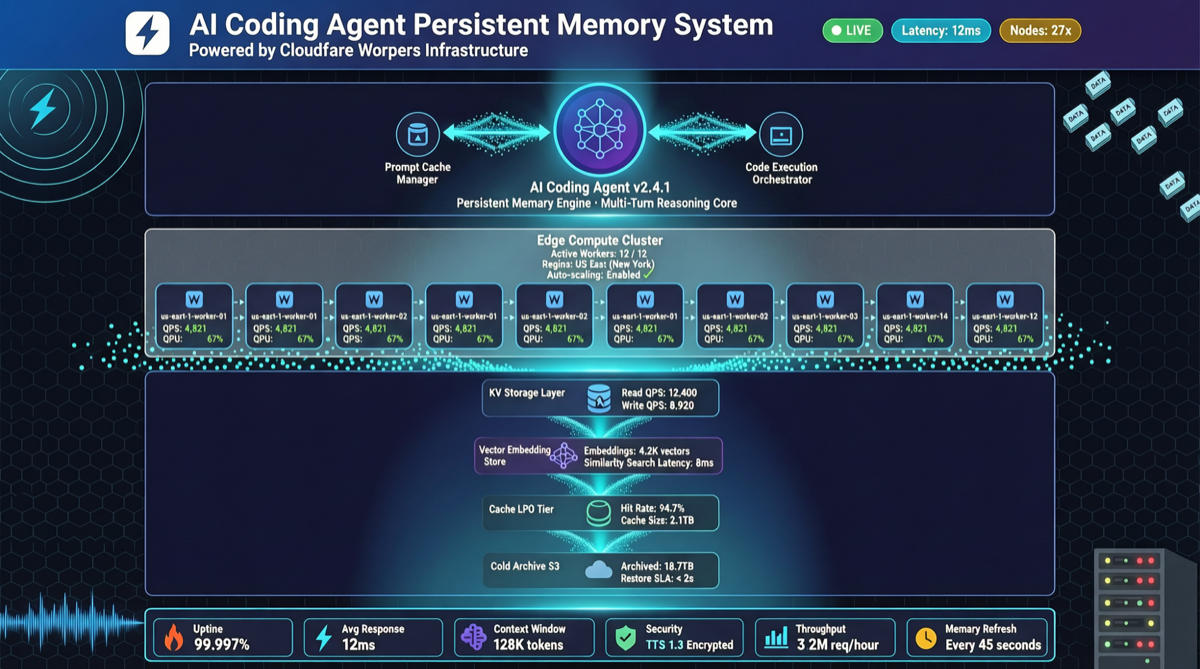
这个由 rohitg00 开发的项目,给 AI 编程 Agent 加了一层持久记忆——项目信息、用户偏好、历史决策都存在 Cloudflare Workers 上,Agent 启动时自动加载。目前 3.3k stars,昨天一天涨了 518 星。
它做了什么
核心理念很简单:Agent 不应该每次从零开始。
Agentmemory 提供三个能力:
- 项目上下文持久化:目录结构、技术栈、编码约定自动记录,下次 Agent 启动时自动恢复
- 跨会话记忆:上次 Agent 踩过的坑、做出的架构决策,下次还能记得
- 搜索召回:通过语义搜索从历史记忆中召回相关信息,而不是把整个上下文塞给 Agent
最新版本 v0.9.5 还加了搜索召回和插件兼容性——这个版本号看起来不大,但 changelog 提到 v0.9.5 做了 "sandbox-model shift",说明底层架构有变化。
集成情况
这是 Agentmemory 最有竞争力的地方——它不是绑死在某个 Agent 上的。目前支持:
- Claude Code(
.claude-plugin目录在仓库里) - OpenClaw(仓库的
integrations/目录下有 Hermes 的集成修复,最近 8 小时还在更新) - Codex
- 其他通过 MCP 协议接入的 Agent
对 OpenClaw 和 Hermes Agent 用户来说,这意味着你可以直接在现有工作流中加上记忆层,不需要换 Agent。
架构
基于 Cloudflare Workers 构建,这意味着:
- 免费额度够用:Cloudflare Workers 的免费层对于个人开发者的 Agent 记忆存储绰绰有余
- 全球低延迟:记忆数据就近存储和读取
- 不用自己运维数据库:这是和自建向量数据库方案的最大区别
仓库里有 benchmark/ 目录,说明作者做了性能测试。README 声称 "based on real-world benchmarks"——#1 这个称号怎么来的不清楚,但有 benchmark 总比没有强。
值不值得装
如果你的工作流是这样的:
每天用 Claude Code / Codex / OpenClaw 做编码,项目上下文每次都要重新喂
值得装。 5 分钟配置,后面每次都能省掉重新交代项目背景的 Token 消耗。作者声称能省 40% Token,我没实测过这个数字,但从原理上说得通——记忆召回比全量上下文便宜得多。
如果你的工作流是这样的:
偶尔用 Agent 写个小脚本,用完就关
不用装。 记忆层的价值在于累积,偶尔用一次的项目不需要持久记忆。
隐患
- Cloudflare Workers 依赖:如果 Workers 出问题,记忆就断了。作者应该考虑降级方案
- 隐私问题:项目代码和架构决策存在第三方云上,企业用户可能需要自建部署
- 274 commits 但只有 330 forks,社区参与度不算高
主要来源: