Letting AI run research sounds great. But after a month of running, you look back at the results—are the conclusions solid? Is the evidence chain complete? Or did the model fabricate something that looks reasonable but falls apart under scrutiny?
This is the core failure mode of autonomous research systems—not an obvious crash, but a "looks successful but evidence is thin" outcome. A paper from Shanghai Jiao Tong University, published May 4, tackles this problem head-on.
Core Design: One Works, One Critiques
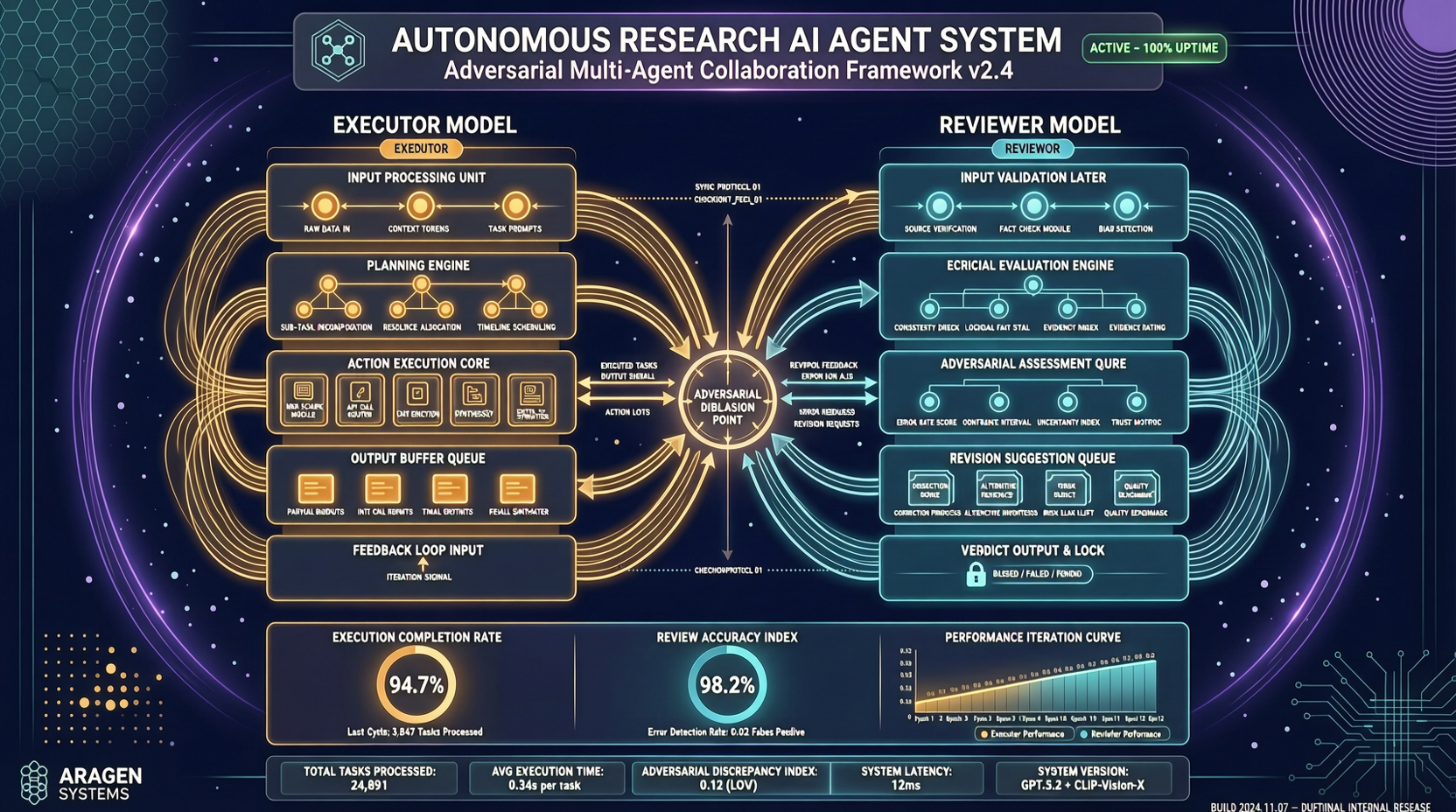
ARIS stands for "Autonomous Research via Adversarial Multi-Agent Collaboration."
The architecture is simple but not naive: an executor model drives research progress forward, while a reviewer model from a different model family critiques intermediate artifacts and requests revisions. The default configuration is adversarial.
This design is intuitively right. A single model falls into its own thinking patterns. A reviewer from a different architecture catches different blind spots. It's like getting peer review from someone in a different field—more useful than getting it from your lab mate.
Three Layers, Not Just "Run an Agent"
ARIS is not simply calling an API and having the model write a paper. It has three layers:
The execution layer provides over 65 reusable Markdown-defined skills, model integrations via MCP, and a persistent research wiki for iterative reuse of prior findings. Deterministic figure generation is also a notable feature—research paper figures can't look different every time you regenerate.
The orchestration layer coordinates five end-to-end workflows, with adjustable effort settings and reviewer model routing.
The assurance layer is where this paper gets interesting. A three-stage process checks whether experimental claims are supported by evidence: integrity verification, result-to-claim mapping, and claim auditing (cross-checking manuscript statements against the claim ledger and raw evidence). Plus a five-pass scientific editing pipeline and mathematical proof checking.
10,300 GitHub Stars, 119 Upvotes
That's eye-catching on Hugging Face Daily Papers. It shows the community's interest in "AI doing research autonomously" is real, not hype.
But Don't Get Excited Yet
The paper itself notes this is a prototype. The self-improvement loop records research traces that need reviewer approval before adoption—meaning the system doesn't yet trust its own improvement suggestions.
More importantly, adversarial review reduces "looks right but isn't" conclusions, but it can't eliminate the model's knowledge boundaries. If neither the executor nor the reviewer knows the facts in a domain, adversarial collaboration won't save you.
A Practical Question
What I care about: how do papers produced by ARIS compare to what a human grad student writes in two weeks? Where's the gap? Literature review completeness? Experimental design? Writing quality?
The paper doesn't provide this comparison. But if someone runs ARIS on a known-result课题 (like reproducing a classic paper's experiments), the results would be interesting.
Primary sources:
- ARIS paper (Shanghai Jiao Tong University, May 4, 2026)
- Hugging Face Daily Papers (119 upvotes)
- GitHub: 10,300 stars