Звучит заманчиво: пусть ИИ сам проводит исследования. Но если через месяц оглянуться назад, будут ли выводы обоснованными? Цепочка доказательств будет полной? Или модель просто сгенерирует правдоподобную на вид, но не выдерживающую критики цепочку рассуждений?
Это ключевой режим отказа автономных исследовательских систем — не явный крах, а ситуация «выглядит как успех, но доказательств недостаточно». Исследовательская группа Шанхайского университета Цзяотун в статье об ARIS, опубликованной 4 мая, напрямую столкнулась с этой проблемой.
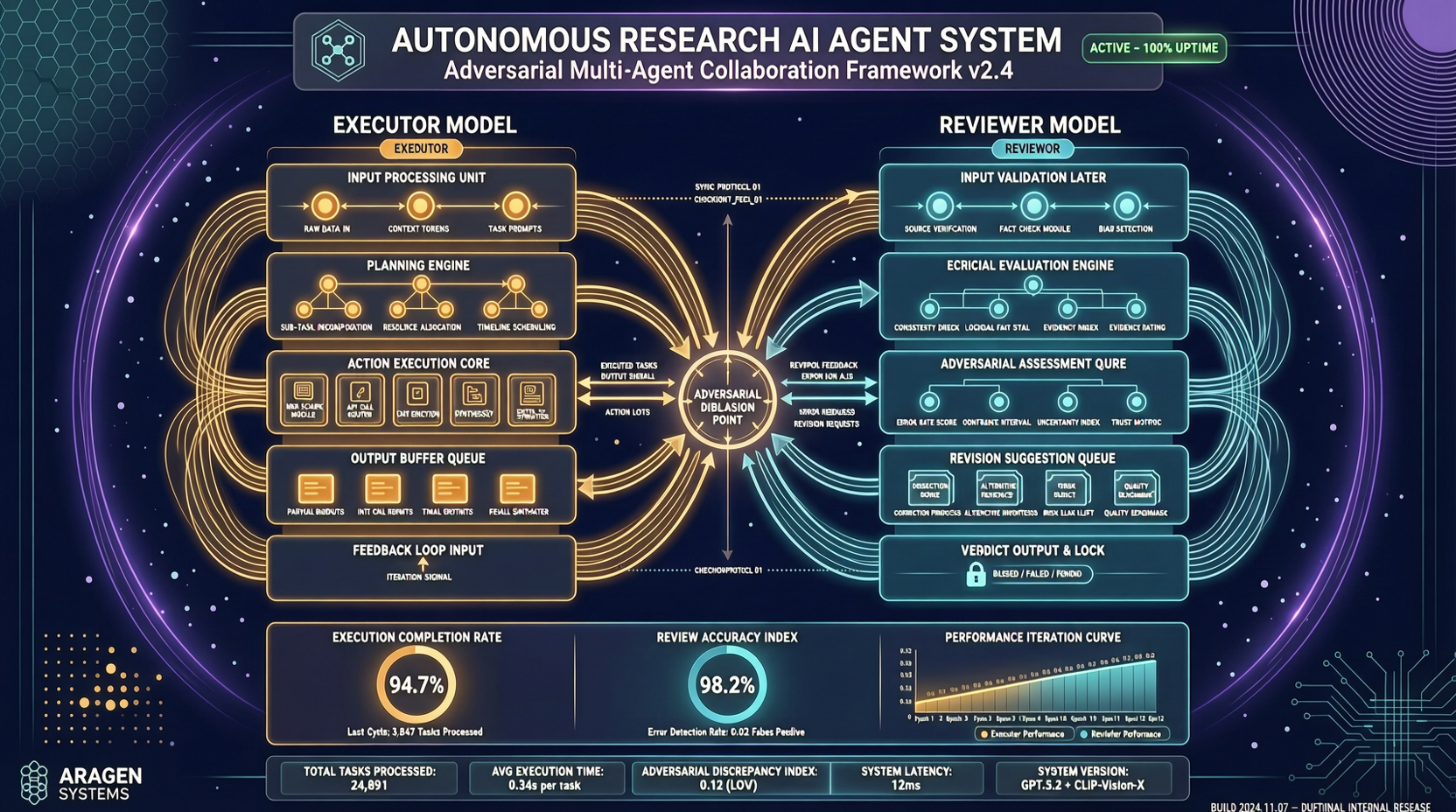
Ключевая архитектура: один работает, другой критикует
ARIS расшифровывается как "Autonomous Research via Adversarial Multi-Agent Collaboration" (Автономные исследования посредством состязательного взаимодействия мультиагентных систем).
Архитектура проста, но не примитивна: модель-исполнитель (executor) отвечает за продвижение исследования, а модель-рецензент (reviewer) из другого семейства моделей критикует промежуточные результаты и требует доработок. Конфигурация по умолчанию является состязательной.
Интуитивно этот подход кажется верным. Одна модель легко попадает в собственные когнитивные искажения, а привлечение модели с другой архитектурой для проверки значительно сокращает слепые зоны. Это похоже на поиск рецензентов из смежных областей при написании статьи — это полезнее, чем просить об этом своего однокурсника.
Трёхуровневая архитектура: не просто «запустить агента»
ARIS — это не просто вызов API, чтобы модель написала статью. Система состоит из трёх уровней:
Исполнительный уровень предоставляет более 65 переиспользуемых навыков, определённых в Markdown, интегрирует различные модели через MCP и включает постоянную исследовательскую wiki для итеративного повторного использования предыдущих находок. Детерминированная генерация графиков — ещё одна важная особенность: графики в научных статьях не должны каждый раз выглядеть по-разному.
Уровень оркестрации координирует пять сквозных рабочих процессов, поддерживает настраиваемые параметры нагрузки и маршрутизацию моделей-рецензентов.
Уровень обеспечения качества — самая ценная часть статьи. Трёхэтапный процесс проверяет, подтверждены ли экспериментальные утверждения доказательствами: проверка полноты, сопоставление результатов с утверждениями, аудит утверждений (перекрёстная проверка формулировок рукописи с реестром утверждений и исходными доказательствами). Дополнительно включены пятиэтапный процесс научного редактирования и проверка математических доказательств.
10 300 звёзд на GitHub, 119 голосов
Эти цифры весьма заметны в HuggingFace Daily Papers. Они показывают, что интерес сообщества к теме «ИИ, самостоятельно проводящий исследования» вполне реален, а не просто хайп.
Но не спешите радоваться
Авторы статьи сами отмечают, что это прототип. Записи исследовательских следов (research traces) в цикле самосовершенствования (self-improvement loop) должны быть одобрены рецензентом, прежде чем будут приняты — это означает, что система пока не доверяет собственным рекомендациям по улучшению.
Что ещё важнее, состязательная проверка снижает количество выводов, которые «кажутся верными, но на самом деле ошибочны», однако не устраняет границы знаний модели. Если ни исполнитель, ни рецензент не владеют фактами в определённой области, состязательный подход их не спасёт.
Практический взгляд
Меня больше всего интересует следующее: в чём заключается разница в качестве между статьёй, сгенерированной ARIS, и работой, которую аспирант-человек писал бы две недели? Недостаточно полный обзор литературы, пробелы в дизайне эксперимента или проблемы с изложением?
В статье не приведено сравнения по этому параметру. Однако было бы очень интересно, если бы кто-то использовал ARIS для исследования с уже известным результатом (например, для воспроизведения эксперимента из классической статьи).
Основные источники:
- Статья об ARIS (Shanghai Jiao Tong University, 4 мая 2026 г.)
- Hugging Face Daily Papers (119 upvotes)
- Репозиторий GitHub: 10 300 stars