让 AI 自己跑研究,听起来很美好。但跑了一个月回头一看,结论立得住吗?证据链完整吗?还是模型自己脑补了一串看起来合理但经不起推敲的东西?
这是自主研究系统最核心的失败模式——不是显眼的崩溃,而是"看起来成功了但证据不足"。上海交大的研究团队在 5 月 4 日发布的 ARIS 论文,正面撞上了这个问题。
核心设计:一个干活,一个挑刺
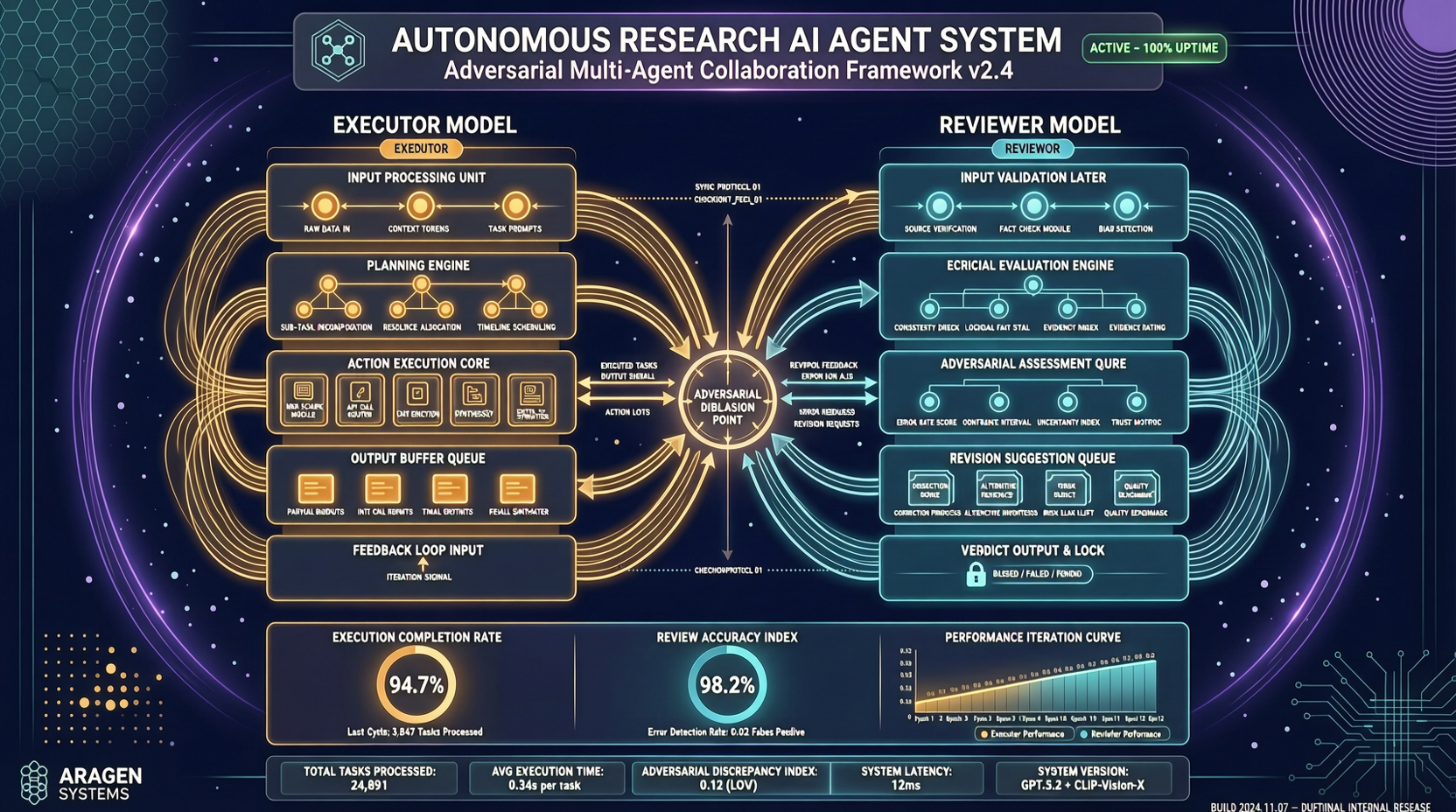
ARIS 的全称是 "Autonomous Research via Adversarial Multi-Agent Collaboration"——对抗式多智能体协作自主研究。
架构很简单但不粗暴:一个执行器模型(executor)负责推进研究进度,一个来自不同模型家族的审查器模型(reviewer)负责批判中间产物并要求修改。默认配置就是对抗式的。
这个设计直觉上很对味。一个模型容易陷入自己的思维定势,换一家不同架构的模型来审查,盲区会少很多。就像写论文时找不同方向的同行评审,比找同门师兄更有用。
三层架构,不只是"跑个 agent"
ARIS 不是简单地调个 API 让模型写论文。它有三层:
执行层提供了超过 65 个可复用的 Markdown 定义技能,通过 MCP 集成多种模型,还有一个持久的研究 wiki 用来迭代复用之前的发现。确定性图表生成也是个亮点——科研论文的图不能每次都长不一样。
编排层协调五个端到端工作流,支持可调的工作量设置和审查器模型路由。
保障层是这篇论文最值得看的地方。三阶段流程用来检查实验声明是否有证据支撑:完整性验证、结果到声明的映射、声明审计(将手稿陈述与声明账本和原始证据交叉核对)。外加五遍科学编辑流程和数学证明检查。
GitHub 10,300 星,119 票
这个数据在 HuggingFace Daily Papers 上相当扎眼。说明社区对"AI 自主做研究"这件事的兴趣是实打实的,不是炒概念。
但别激动
论文自己也说了,这是一个 prototype。self-improvement loop 记录的 research traces 需要经过 reviewer 批准才能被采纳——说明系统本身还不信任自己的改进建议。
更重要的是,对抗式审查能减少"看起来对但实际不对"的结论,但不能消除模型的知识边界。如果执行器和审查器都不知道某个领域的事实, adversarial 也救不了。
一个实际的观察角度
我比较关心的是:ARIS 跑出来的论文,和人类研究生花两周写的相比,质量差距在哪?是文献综述不够全面,还是实验设计有漏洞,还是写作表达有问题?
论文没有给出这个维度的对比。但如果有人拿 ARIS 跑一个已知结果的课题(比如复现某篇经典论文的实验),结果会很有意思。
主要来源:
- ARIS 论文(Shanghai Jiao Tong University,2026 年 5 月 4 日)
- Hugging Face Daily Papers(119 upvotes)
- GitHub 仓库:10,300 stars