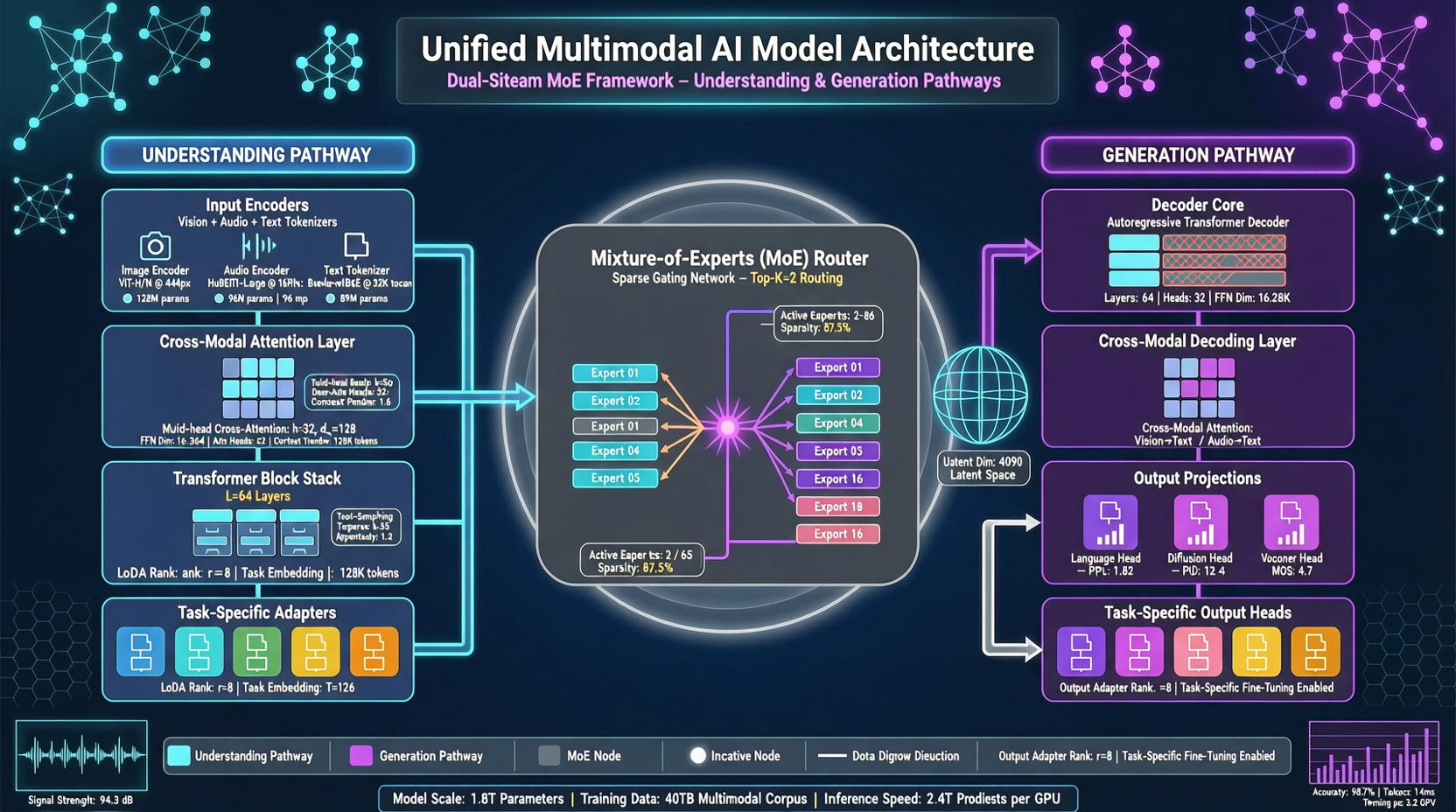
Anyone building unified multimodal models knows an uncomfortable truth: understanding and generation, when stuffed into the same model, drag each other down. Understanding tasks demand precision. Generation tasks demand creativity. During training, both are essentially fighting for the same feature pathway.
ByteDance's research team submitted a paper on May 18 with a different approach. No massive parameter stacking. No "text-image dominant" legacy path. Instead, they split the understanding and generation pathways—sharing context, but doing their own work.
The project is called Lance.
Shared Brain, Separate Outputs
Lance's architecture has an intuitive analogy: like a person listening and speaking at the same time. Both share the same brain (shared context modeling), but auditory processing and language output run on separate neural pathways (decoupled capability pathways).
Specifically, Lance trains from scratch with a dual-stream mixture-of-experts (dual-stream MoE) architecture, operating on shared interleaved multimodal sequences. All modality tokens enter the model together to learn joint context, but understanding and generation tasks each take their own expert paths.
This is not a cascade of "understand first, then generate." Understanding and generation advance simultaneously during training, with MoE routing directing different sub-networks to focus on different capabilities.
Two Key Design Choices
First: modality-aware rotary positional encoding. When tokens from different modalities—image patches, video frames, text tokens—mix together, standard positional encoding causes mutual interference. Lance adds modality-specific positional encoding identifiers, letting the model distinguish "this is a visual signal" from "this is a text signal," reducing cross-modal interference.
Second: staged multi-task training. Not dumping understanding, generation, and editing all at once. Instead, Lance progresses through stages, each with clear capability objectives, paired with adaptive data scheduling. Build the foundation first, then strengthen.
How Does It Perform
The paper claims Lance substantially outperforms existing open-source unified models in image and video generation, while maintaining strong multimodal understanding.
69 upvotes on Hugging Face Daily Papers. Not explosive, but solid for this direction.
What I'm Watching
The Lance homepage should show concrete generation samples and comparisons. If its video generation quality genuinely leads existing open-source alternatives, ByteDance has carved out its own path in unified multimodal modeling.
But the paper is less than a week old. Real community validation is still thin. MoE training stability and inference routing efficiency—these only show up in real deployment.
Why This Direction Matters
Unified multimodal models aren't new. But most approaches lean either toward understanding (MLLMs) or generation (diffusion/flow models), or brute-force parameter scaling to cover both. Lance represents a more pragmatic route—enabling understanding and generation to coexist within limited model capacity through architectural design.
If this works, the future might not need separate models for understanding and generation. One model, two capabilities, costs cut in half.
Primary sources:
- Lance paper (ByteDance Research, May 18, 2026)
- Hugging Face Daily Papers (69 upvotes)
- Project page: https://lance-project.github.io/