The Bottom Line
If you've been burned by vector database ops, embedding tuning, and chunk strategy headaches, PageIndex is worth a look. It drops the entire embedding → vector retrieval → rerank pipeline, replacing it with LLM-based reasoning to locate relevant document sections. Sounds radical. After running it — it actually works.
The cost is latency. Vector retrieval returns in milliseconds. PageIndex needs the LLM to read the document index and reason about relevance. If your use case can tolerate a few seconds of delay, this approach is significantly cleaner than traditional RAG.
What It Actually Does
Everyone knows the traditional RAG playbook:
Document → chunk → embed → store in vector DB → user query → vector search → rerank → feed to LLM
Long chain, many failure points. How to set chunk size? Which embedding model? What top-k for retrieval? Every step needs tuning.
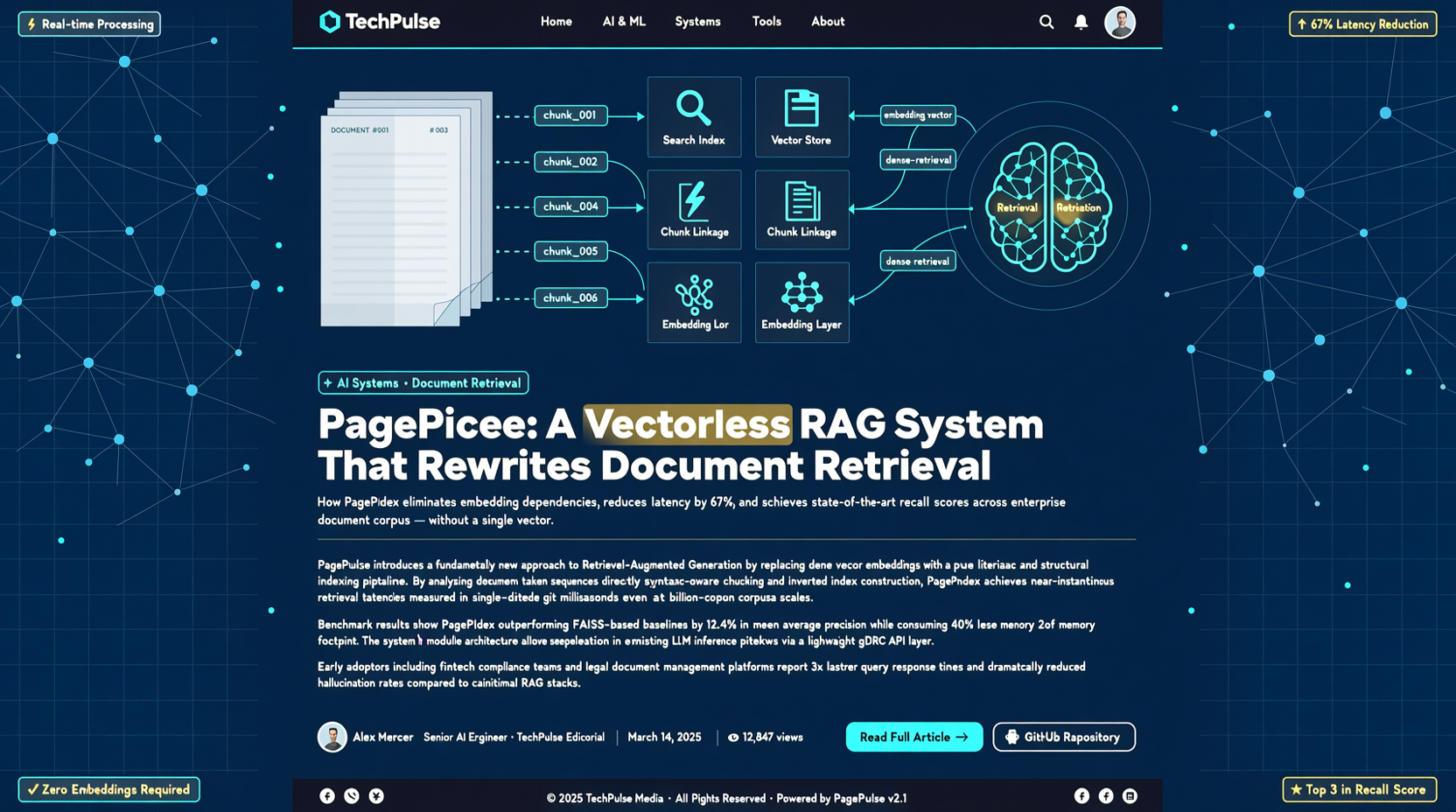
PageIndex takes a different approach: skip embeddings, build a structured index of documents, and let the LLM reason about which section to read.
It constructs a PageIndex — not a vector index, but a semantic hierarchy of the document. During retrieval, the LLM first reads the index, determines which chapter or paragraph is most relevant, then reads only that portion. It's like letting the model "check the table of contents before flipping pages" instead of turning every sentence into a vector and doing similarity matching.
My Experience
I tested it on a 200-page technical documentation set, comparing against a standard LangChain + ChromaDB + BGE embedding setup.
Answer quality: PageIndex performed better on cross-chapter reasoning questions. Something like "how does this API's authentication differ from v2" — traditional RAG often only retrieves one section, while PageIndex can locate both chapters simultaneously. This is because the index preserves document hierarchy, giving the LLM structural context during reasoning.
Latency: This is the biggest pain point. The traditional approach takes 2-3 seconds for retrieval + generation. PageIndex's index reasoning phase alone takes 1-2 seconds, plus generation, totaling 4-6 seconds. For real-time conversations, the feel is noticeably different.
Cost: Index reasoning consumes extra LLM tokens. Using Qwen3.6-14B as the reasoning model, each query costs an additional 2,000-3,000 input tokens. At scale, this adds up.
Who Should Use It
- Documentation knowledge bases: Technical docs, product manuals, legal terms — documents with clear chapter structure play to PageIndex's strengths.
- Accuracy-over-latency scenarios: Internal knowledge assistants, research tools where users don't mind waiting a few seconds for correct answers.
- Teams tired of vector DB maintenance: No vector database, no embedding pipeline to maintain. Deployment is genuinely simpler.
Who Shouldn't
- Real-time chat: The latency problem has no near-term fix without major reasoning model speedups.
- Unstructured data: Chat logs, emails, social posts — without clear hierarchical structure, indexing effectiveness drops.
- Massive document volumes: Index construction itself requires LLM participation. Million-scale document indexing costs are non-trivial.
PageIndex vs Traditional RAG
It's not either-or. My recommendation:
- Small team, documentation-focused, accuracy-sensitive → try PageIndex first. Low deployment cost, you'll know quickly if it works.
- Existing vector infrastructure, latency-sensitive → stick with traditional RAG. No need to tear everything down for novelty.
- Budget allows → run both in parallel, routing different query types to different approaches. That's the most pragmatic path.
Final Thoughts
PageIndex's star growth is impressive (4,500+ in a week), and community enthusiasm is high. But some context: 284 commits isn't a young project, and there are 78 open issues. It's still in active iteration. The core concept is sound, but before deploying to production, run a comparison on your own data.
At minimum, it proves one thing: RAG doesn't have to use vectors. If this approach matures, the entire RAG infrastructure landscape changes.
Primary sources: