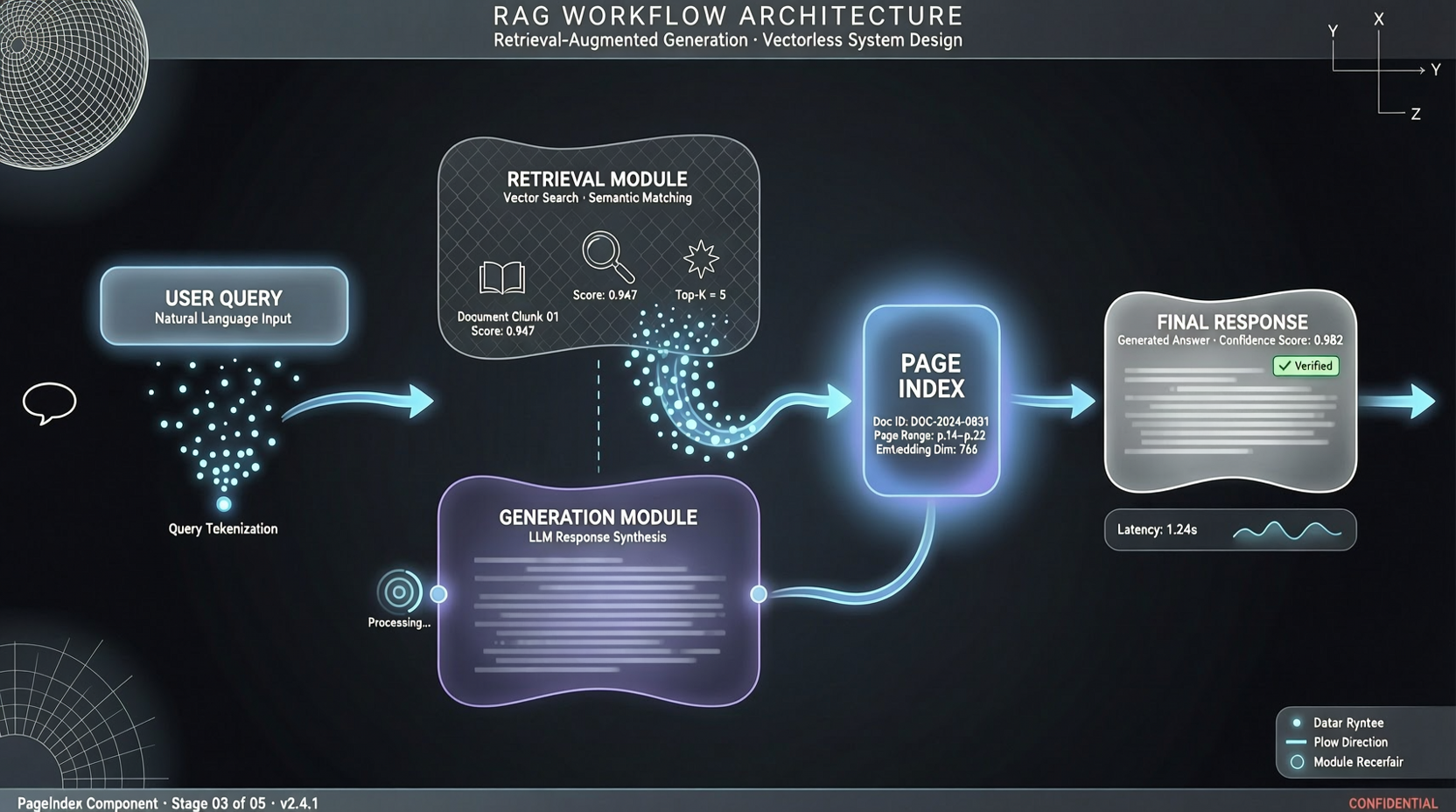
RAG (Retrieval-Augmented Generation) has been around for years. Most people do it the same way: chunk documents → vectorize → store in vector database → query with semantic similarity matching → feed the most similar fragments to the LLM.
This pipeline has a long-standing complaint: vector similarity doesn't equal information relevance. Two texts being close in vector space doesn't mean they're logically related.
PageIndex wants to try a different approach.
What It Is
PageIndex is VectifyAI's open-source "document index" system, featuring vectorless, reasoning-based RAG.
Core idea: instead of vectorization, build structured indexes for documents. When querying, instead of finding "most similar" fragments via vector similarity, let the model reason about which parts should be retrieved, then extract precisely by index.
30,800 stars, up 4,555 this week. 284 recent commits, last update 20 hours ago. Project activity is solid.
Difference from Traditional Vector RAG
| Traditional Vector RAG | PageIndex | |
|---|---|---|
| Indexing | Vectorization + vector DB | Structured document index |
| Retrieval | Semantic similarity matching | Reasoning-based retrieval |
| Dependencies | Needs vector DB (Pinecone/Milvus etc.) | No vector DB needed |
| Accuracy | Limited by vector expressiveness | Limited by model reasoning ability |
In short: turn "retrieval" from a "matching problem" into a "reasoning problem."
Pros and Cons
Advantages:
- No need to deploy and maintain a vector database — architecture simplified significantly
- For scenarios needing precise matching (legal clauses, technical docs), reasoning-based retrieval may be more accurate than semantic similarity
- Index updates are faster — modifying index structure is lighter than re-vectorizing an entire document corpus
Costs:
- Each retrieval requires calling an LLM for reasoning — latency and cost are higher than vector matching
- If the model's reasoning ability isn't strong enough, retrieval quality drops directly
- Building indexes for large document corpora also has its own cost
Who It's For
Professional domains needing high-precision retrieval. Law, healthcare, technical docs — where "a small miss is a big miss." Vector similarity might bring in irrelevant clauses; reasoning-based retrieval can pinpoint more precisely.
Teams that don't want to maintain vector databases. Vector DB ops costs are underestimated — sharding, backup, index updates, version upgrades. If your team doesn't have dedicated infra people, PageIndex's architecture is friendlier.
Scenarios with clear document structure. If documents are already structured (API docs, product manuals, specifications), PageIndex's structured indexing can maximize its advantage.
Who It's Not For
- High-concurrency, low-latency scenarios. If you need millisecond responses, vector retrieval is still better. Reasoning-based retrieval latency depends on model response speed.
- Ultra-large-scale unstructured documents. For massive unstructured text, vectorization's scaling capability is still stronger.
My Take
PageIndex isn't trying to "replace" vector RAG — it's offering an alternative path.
2025's RAG keyword was "vector database." 2026 might become "diversification of retrieval strategies." Vector RAG suits large-scale, low-cost, error-tolerant scenarios. PageIndex suits small-scale, high-precision scenarios willing to pay extra cost (inference time and API fees) for accuracy.
If your current vector RAG isn't performing well, especially if it frequently retrieves irrelevant content, PageIndex is worth trying. But if your vector RAG is running fine, no need to migrate just to chase the new — tools serve you, not the other way around.
Main sources:
- GitHub - VectifyAI/PageIndex (repository analysis)
- GitHub Trending Weekly (popularity tracking)
- Traditional vector RAG architecture comparison