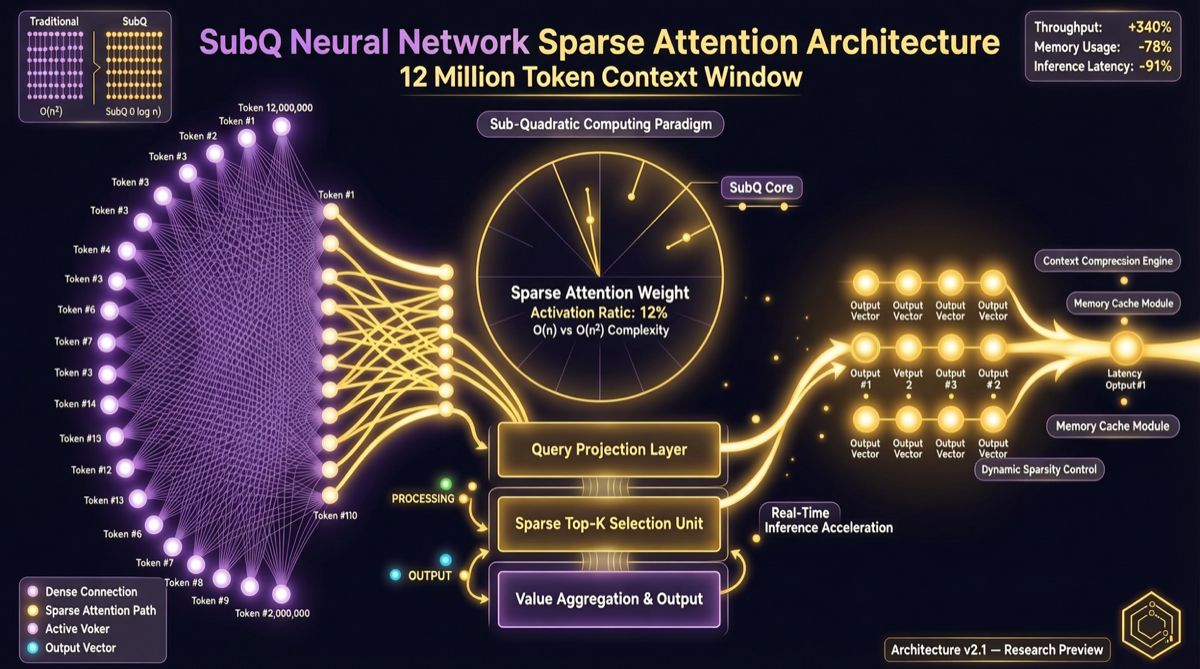
Bottom Line First
SubQ is not "just another bigger context window" — it is the first frontier LLM built entirely on a Subquadratic Sparse Attention (SSA) architecture. 12 million token context, 52x faster than FlashAttention, less than 5% of Claude Opus cost — behind these numbers lies a more fundamental shift: Transformer attention is no longer the only answer for long context.
Three Shocking Numbers
| Metric | Data | Compared To |
|---|---|---|
| Context Window | 12 Million Tokens | 6-94x larger than mainstream models at 128K-2M |
| Attention Speed | 52x Faster (at 1M tokens) | Compared to FlashAttention |
| Inference Cost | Under 5% | Compared to Claude Opus |
This tweet received 22K likes and 2.8K retweets — the community reaction shows this is no ordinary product update.
What SSA Architecture Actually Is
Traditional Transformer attention is all-to-all (dense):
Traditional Attention:
Every token looks at every other token
Computational complexity: O(n²)
12M tokens → 144 trillion operations → impossible
SSA (Subquadratic Sparse Attention) approach:
Sparse Attention:
Each token only looks at "relevant" tokens
Computational complexity: Sub-quadratic O(n^k), k<2
12M tokens → computable → practical
Key differences:
| Dimension | Traditional Transformer | SSA (SubQ) |
|---|---|---|
| Attention Pattern | All-to-all (dense) | Sparse selection |
| Computational Complexity | O(n²) | Sub-quadratic O(n^k), k<2 |
| Long Context Efficiency | Degrades rapidly | Near-linear scaling |
| Memory Usage | Grows quadratically with context | Near-linear growth |
Why 12M Tokens Matters
This isn't "bigger is better" number-gaming — 12 million tokens unlock entirely new use cases:
- Full novel analysis: War and Peace is ~560K words, 12M tokens can load 20+ full novels simultaneously
- Complete codebases: All code + documentation + commit history of a mid-size project loaded at once
- Full legal case files: Entire case dossiers as context, no chunking needed
- Genomic data analysis: DNA sequences as direct input
- Video content understanding: Ultra-long context modeling of video frame sequences
Comparison with Existing Long-Context Solutions
| Solution | Max Context | Architecture | Cost | Practical Usability |
|---|---|---|---|---|
| SubQ | 12M Tokens | SSA | Very Low | ✅ Native support |
| Gemini 3.1 Ultra | 2M Tokens | Transformer | Medium | ✅ Usable |
| Claude Opus 4 | 200K Tokens | Transformer | High | ⚠️ Expensive |
| GPT-5.5 | 128K Tokens | Transformer | High | ⚠️ Expensive |
| DeepSeek V4 | 1M Tokens | MoE Transformer | Low | ✅ Usable |
SubQ leads by an order of magnitude in context length while being lower cost.
But Caveats Apply
1. The Trade-off of Sparse Attention
- Not all relationships between tokens are modeled
- May have precision loss on tasks requiring global precise associations
- Sparse pattern selection is a critical hyperparameter
2. Ecosystem Maturity
- New architecture means toolchains and fine-tuning frameworks need adaptation
- Community resources far less rich than Transformer ecosystem
- Production deployment requires self-validation
3. Benchmark Transparency
- Currently published data focuses mainly on speed and cost
- Performance on standard benchmarks (MMLU, SWE-Bench, etc.) needs more validation
- The conditions for "under 5% cost" comparison need further confirmation
Landscape Assessment
SubQ's release marks an important signal in AI model architecture: next-generation architectures beyond Transformer are moving from papers to reality.
For the past two years, LLM competition has focused on "bigger models + more data." SubQ proves that architectural innovation may deliver greater returns than scale expansion. If SSA architecture validates its capabilities on more benchmarks, it could become the default choice for long-context scenarios.
How to Use It
| Scenario | Recommendation |
|---|---|
| Ultra-long document analysis | Replace traditional solutions directly, 12M context eliminates chunking |
| Codebase-level understanding | Load entire repos, agents see complete project structure |
| Cost-sensitive scenarios | Under 5% cost is attractive for large-batch processing |
| Experimental projects | Try SSA architecture performance in new scenarios |
| Production environments | Recommend validating in non-critical scenarios first, wait for more benchmark data |
What to Watch Next
- SubQ's performance on standard benchmarks like SWE-Bench, MMLU
- Community tools for SSA architecture fine-tuning and adaptation
- Whether other model vendors follow the sparse attention route
- Whether SSA has advantages in short-context scenarios (<100K tokens)