プレスリリースなし、論文だけ
DeepSeekのアプローチは一貫している。マーケティングのプレスリリースも、ローンチのライブ配信もない。arXivに静かに論文が現れ、AIコミュニティ全体が共有モードに入るだけだ。
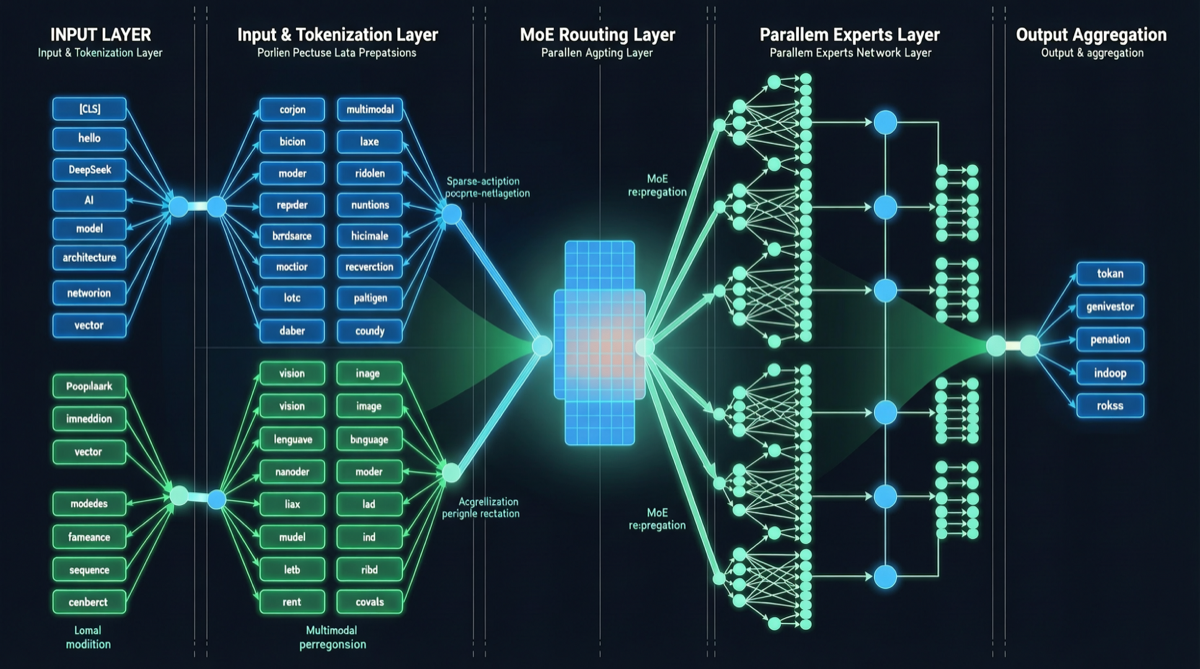
「Thinking with Visual Primitives」は、DeepSeekのマルチモーダル大規模言語モデルの完全な技術アーキテクチャを詳述している。「XXモデルにビジョンエンコーダーをくっつけた」といった継ぎ接ぎ的なものではなく、視覚表現から言語推論までのエンドツーエンドの設計だ。
アーキテクチャ分解
基盤:DeepSeek-V4-Flash
モデルはDeepSeek-V4-Flash上に構築されており、エキスパート混合(MoE)言語アーキテクチャを採用:
- 総パラメータ数:284B
- 活性化パラメータ数:13B
- 推論効率:推論時に総パラメータの約4.6%のみを活性化
大規模モデルの能力を維持しながら、推論コストを驚くほど合理的なレベルに抑えている。マルチモーダルシナリオでは、この効率の利点がさらに顕著になる。
ビジョンエンコーダー:DeepSeek-ViT
これが論文の真の亮点だ。既存のCLIPやSigLIPを使うのではなく、DeepSeekは独自のDeepSeek-ViTを開発した:
- パッチ戦略:14×14の標準パッチサイズ、ViT-Largeと一貫
- 空間圧縮:ビジョンエンコーダー出力後に3×3空間圧縮層を接続、シーケンス長を1/9に削減
- 統合:圧縮されたビジョントークンが直接LLM入力シーケンスに供給
空間圧縮ステップが鍵となる。圧縮されていない高解像度視覚入力は数千のトークンを生成し、コンテキストウィンドウとアテンション計算に多大な負担をかける。3×3圧縮は十分な空間情報を保持しながら、ビジョントークン数を管理可能な範囲に抑える。
コアアイデア:「Visual Primitivesで考える」
タイトルにある「Visual Primitives」はギミックではない。コア哲学は、モデルが視覚表現レベルで「考える」ことにある。
- 階層的視覚表現:モデルは異なるレベルで視覚情報を理解する
- クロスモーダルアライメント:視覚プリミティブと言語概念が表現空間でアライメント
- 推論チェーン統合:視覚情報がモデルのchain-of-thought推論プロセスに参加
なぜ重要なのか
DeepSeekはマルチモーダルアプローチにおいて、主流とは異なる選択をした:
外部ビジョンモデルへの依存なし。MoE+マルチモーダルの組み合わせは稀だ。3×3空間圧縮はシンプルだが実践的に極めて効果的。
まとめ
DeepSeekはこの論文で重要な質問に答えた。マルチモーダル大規模モデルはdenseアーキテクチャのパスをたどる必要があるのか? 答えは明らかにノーだ。
オープンソースマルチモーダルモデルに焦点を当てる研究者や開発者にとって、この論文は注意深く読む価値がある。