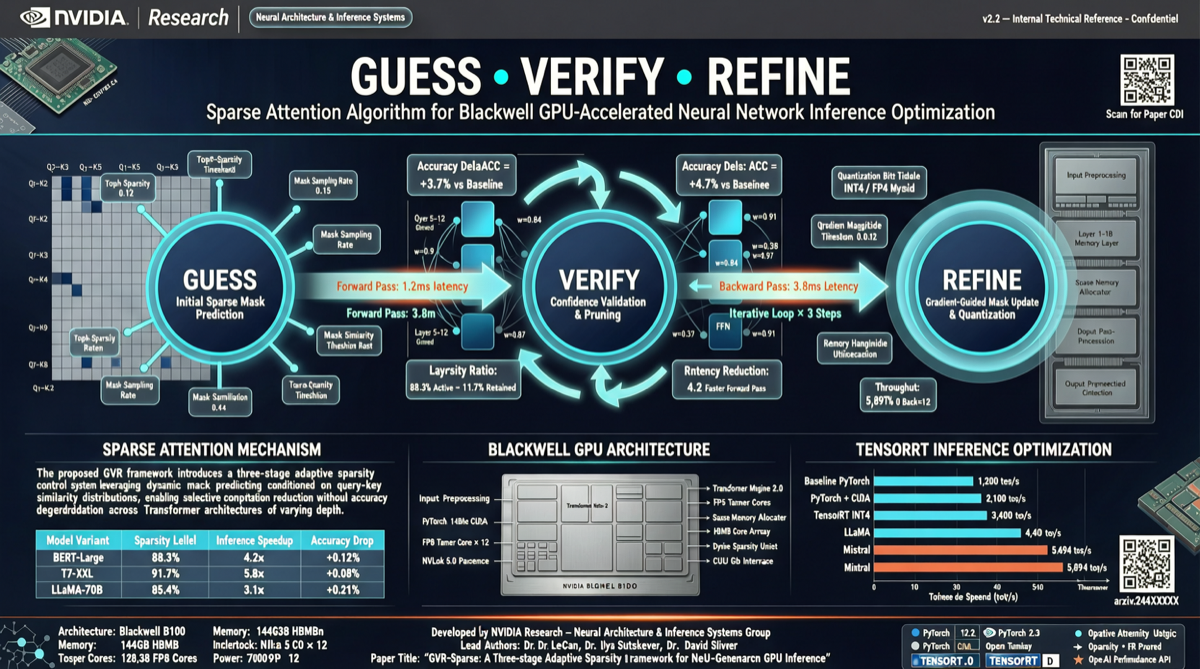
推論速度の話になると、今や競争はモデルサイズではなく、ハードウェアから如何に一滴のパフォーマンスを絞り出すかだ。
NVIDIA Research が今日 X 上で Guess-Verify-Refine という新アルゴリズムを発表した。Blackwell GPU 上の TensorRT-LLM 向けに設計されている。核心のアイデアは驚くほどシンプルだ:隣接するデコードステップ間の時間パターンを再利用する——前のステップで計算したものを次のステップの「事前予測」として使い、検証・修正する。
結果は Top-K 注意機構の 1.88 倍高速化。
アルゴリズムの仕組み
LLM の自己回帰デコードには一つの特性がある:隣接ステップ間の注意パターンはしばしば高い類似性を持つ。前のステップで「最も重要」だったものは、次のステップでもおそらく似ている。
Guess-Verify-Refine はこの直感をアルゴリズムに変えた:
- Guess:前のステップの Top-K 結果を現在のステップの候補として使用
- Verify:これらの候補が現在のステップでも有効か検証
- Refine:満たさない部分に対して補完計算
これは本質的にハードウェア認識のスパース注意戦略だ——毎回フルの注意を計算するのではなく、サブセットを推測し、検証し、必要なら追加する。投機的デコードと精神は似ているが、トークン生成ではなく注意計算自体をターゲットにしている。
なぜ Blackwell で効果的なのか
Blackwell アーキテクチャはスパース計算向けの専用ハードウェア最適化を持っている。Tensor Core のスパースモードサポート、より大容量の SRAM キャッシュ、改善されたメモリバンド幅利用率が、「一部を計算し、一部をスキップする」戦略の恩恵を最大化する。
NVIDIA 自身のアルゴリズムが NVIDIA 自身のハードウェアで動く——この優位性は偶然ではない。
実用的な意味
Top-K 注意機構の 1.88 倍高速化がエンドツーエンドの推論速度にどの程度寄与するかは、注意計算が全体推論に占める割合による。長いコンテキストのシナリオでは(コンテキストが長いほど注意計算が重くなる)、増幅効果はより顕著になる。
ただし冷静に見る必要がある:これは NVIDIA Research のアルゴリズムで、現時点では公開のオープンソース実装や第三者による再現はない。1.88 倍がどのような条件、どのようなモデル、どのようなシーケンス長で測定されたか、NVIDIA は完全な詳細を提供していない。
観察ポイント
いくつかの質問を追っている:
- オープンソースのタイミング:NVIDIA Research のアルゴリズムは通常論文で詳細が公開されるが、TensorRT-LLM への統合には追加の時間が必要。
- 汎化性:他の GPU アーキテクチャ(Ampere、Hopper)ではどうか?Blackwell だけで有意な恩恵があるのか?
- コミュニティの再現:llama.cpp や vLLM などのオープンソース推論フレームワークが同様の最適化を追うか?
ハードウェア認識の推論最適化がモデルデプロイにおける最大の差別化要因になりつつある。モデル能力は誰でも API で使える——同じモデルをより速く、より安く走らせられるかこそが、本当の差をつける場所だ。
主なソース:
- NVIDIA Research X 投稿
- NVIDIA Research ブログ(確認待ち)