Когда речь заходит о скорости инференса, конкуренция больше не о размере модели — речь о том, как выжать каждую каплю производительности из железа.
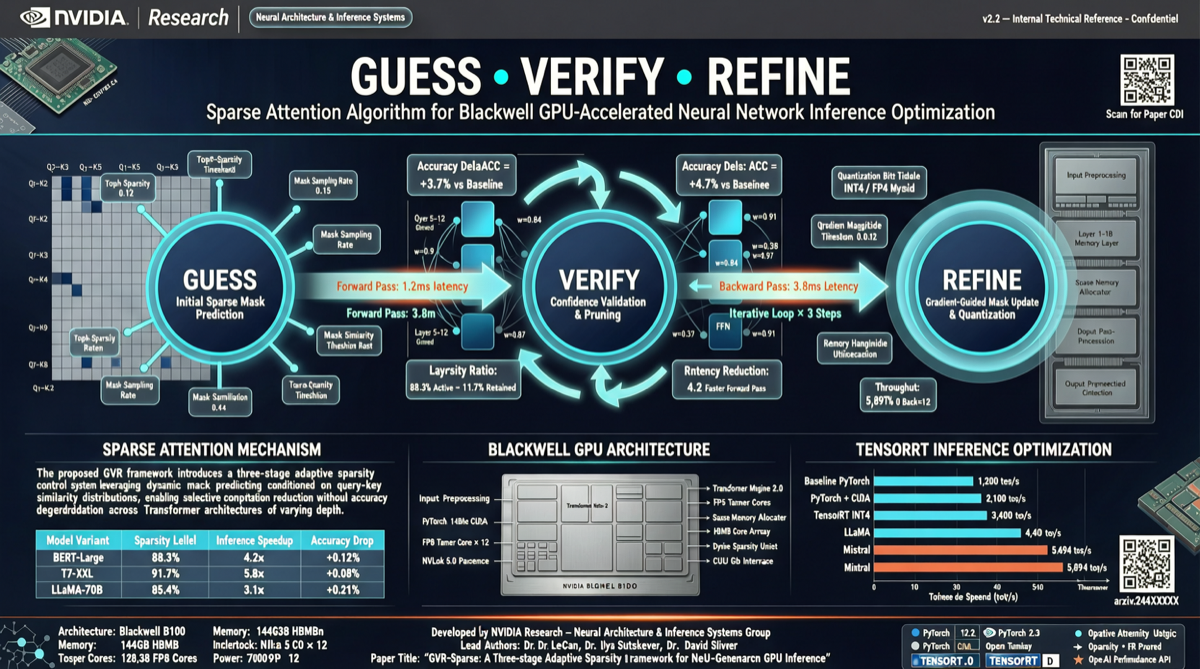
NVIDIA Research сегодня опубликовала в X новый алгоритм под названием Guess-Verify-Refine, предназначенный для TensorRT-LLM на GPU Blackwell. Ключевая идея поразительно проста: повторное использование временных паттернов между соседними шагами декодирования — то, что вычислил предыдущий шаг, становится «предварительным предсказанием» для следующего, затем проверка и уточнение.
Результат: ускорение в 1.88 раза для Top-K внимания.
Алгоритм
Авторегрессионное декодирование в LLM имеет одну характеристику: паттерны внимания между соседними шагами часто сильно похожи. То, что было «наиболее важным» на предыдущем шаге, вероятно, будет похоже на следующем.
Guess-Verify-Refine превращает эту интуицию в алгоритм:
- Guess: Использовать результаты Top-K предыдущего шага как кандидаты для текущего
- Verify: Проверить, остаются ли эти кандидаты действительными для текущего шага
- Refine: Выполнить дополнительные вычисления для частей, которые не удовлетворяют
Это по сути аппаратно-ориентированная стратегия разреженного внимания — не вычислять полное внимание каждый раз, а угадать подмножество, проверить его, и добавить больше при необходимости. Похоже по духу на спекулятивное декодирование, но нацелено на вычисление внимания, а не на генерацию токенов.
Почему это хорошо работает на Blackwell
Архитектура Blackwell имеет специализированные аппаратные оптимизации для разреженных вычислений. Поддержка разреженного режима Tensor Core, увеличенные кэши SRAM и улучшенная утилизация пропускной способности памяти максимизируют выгоду от стратегии «вычисляй часть, пропускай часть».
Собственный алгоритм NVIDIA на собственном железе NVIDIA — это преимущество не случайно.
Практическое значение
Ускорение Top-K внимания в 1.88 раза транслируется в сквозное ускорение инференса в зависимости от доли внимания в общем инференсе. Для сценариев с длинным контекстом (чем длиннее контекст, тем тяжелее вычисление внимания), эффект усиления будет более выраженным.
Но нужно сохранять перспективу: это алгоритм NVIDIA Research без публичной открытой реализации или стороннего воспроизведения. При каких условиях, на каких моделях, при какой длине последовательности было измерено 1.88x? NVIDIA не предоставила полных деталей.
На что обратить внимание
Я отслеживаю несколько вопросов:
- Сроки открытого источника: Алгоритмы NVIDIA Research обычно публикуют детали в статьях, но интеграция в TensorRT-LLM требует дополнительного времени.
- Обобщаемость: Как это работает на других архитектурах GPU (Ampere, Hopper)? Или выгода значима только на Blackwell?
- Воспроизведение сообществом: Последуют ли открытые фреймворки инференса вроде llama.cpp и vLLM с аналогичными оптимизациями?
Аппаратно-ориентированная оптимизация инференса становится главным дифференциатором в развёртывании моделей. Возможности моделей доступны всем через API — но кто может запустить ту же модель быстрее и дешевле, вот что действительно создаёт разрыв.
Связанные материалы:
- Соревнование чипов инференса NVIDIA Rubin
- Архитектурный прорыв разреженного внимания SubQ 12M контекста
Основные источники:
- Пост NVIDIA Research в X
- Блог NVIDIA Research (ожидает подтверждения)