結論
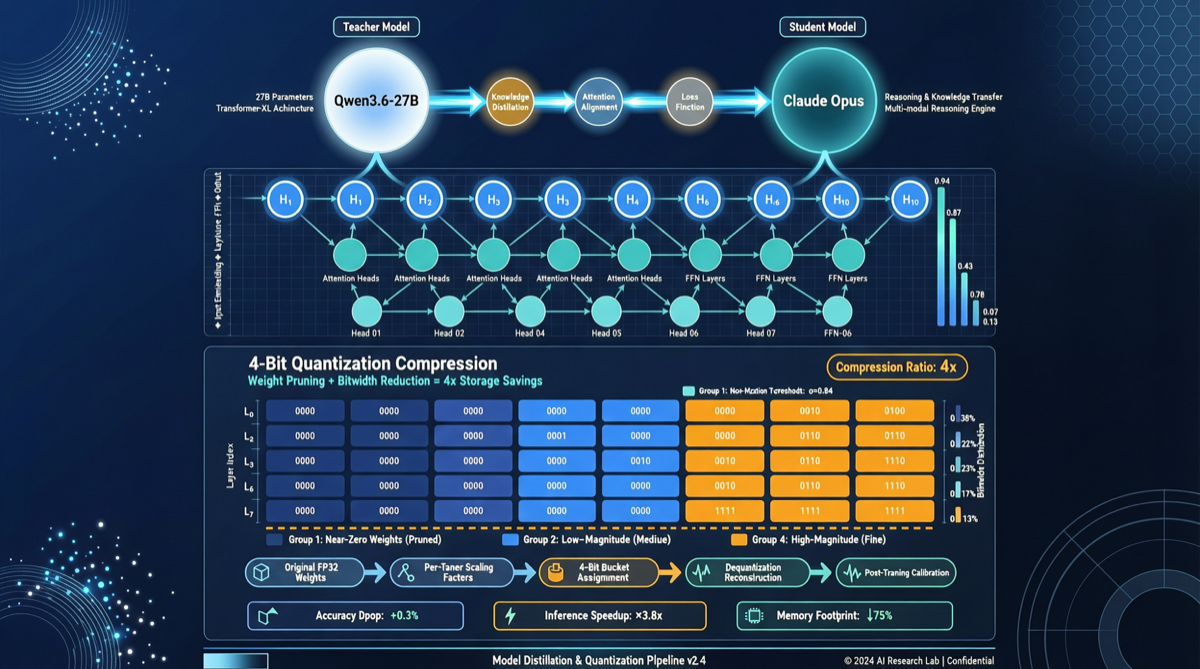
270億パラメータのオープンソースモデルがかつてクローズドソースのフラッグシップモデルにしか提供されていなかった推論能力を、4ビット量子化バージョンにパッケージングしてコンシューマー級GPUに収める——Qwen3.6-27B-Claude-Opus-Reasoning-Distill-v2-int4-AutoRoundのHugging Faceコミュニティへの登場は4,000以上の閲覧と67件のブックマークを巻き起こした。その背後にあるシグナルは明確だ:オープンソース推論モデルの参入障壁が大幅に引き下げられている。
何を蒸留したのか
このモデルの核心となる考え方はシンプルだが効果的だ:
- ベース:Qwen3.5(アリババ・通義千問シリーズの推論最適化版)、27Bパラメータ
- 蒸留ソース:Claude Opus(Anthropicのフラッグシップモデル)の推論トレース
- 量子化:AutoRoundフレームワークのint4量子化方式
蒸留は単なる「出力の模倣」ではない。Opusが複雑な推論タスクにおける思考パス——どのように問題を分解するか、どのように段階的に検証するか、不確実性の中でどのように信頼度を表現するか——を学ぶことだ。
トレーニングの流れはだいたい以下の通り:
- Claude Opusを使って大量の高品質な推論サンプルを生成(数学推論、コード推論、論理チェーン)
- Qwen3.5上でトレーニングし、隠れ状態をOpusの中間表現にアライメントさせる
- AutoRoundで4ビット量子化を適用し、24GB VRAMで実行可能なサイズに圧縮
なぜ27B + 4ビットが重要な数字なのか
この組み合わせは偶然ではない。27Bパラメータのモデルは4ビット量子化後、重みに約13〜14GBのVRAMのみを必要とする。KVキャッシュを含めても、24GBのコンシューマー級GPU(RTX 3090/4090)で完全にロードして実行できる。
主要な数字を比較してみよう:
| モデル | パラメータ数 | 量子化後VRAM | 推論能力レベル |
|---|---|---|---|
| Claude Opus 4 | 〜数千B | ローカル実行不可 | フラッグシップ級 |
| Qwen3.5-72B | 72B | 48GB+(FP16) | 強力な推論 |
| Qwen3.6-27B-int4 | 27B | 〜14GB | Opusに接近 |
これはつまり、個人の開発者が初めて、Opusに迫る推論能力を持つモデルをローカルで実行できるということを意味する。
コミュニティの反応
X/Twitter上の投稿は75件のいいね、67件のブックマークを獲得——AIモデル系投稿としては高いエンゲージメント比率だ。コメント欄の主要な見解は以下の通り:
- “This is advanced text and image reasoning compressed into a 4-bit quantized package”——テキストと画像の推論能力が4ビット量子化パッケージに圧縮された
- 関心はコンシューマーGPUでの実用性とオリジナルOpusとの推論品質のギャップに集中
- すでにローカルにデプロイしてテストしているユーザーもおり、「数学推論とコード生成タスクでのパフォーマンスが期待を超えた」とのフィードバック
国産モデルエコシステムにとっての意味
Qwenシリーズは一貫して「オープンソース + 強力な推論」の路線を歩んできた。今回の蒸留バージョンの登場はいくつかの次元で記念碑的な意味を持つ:
- クローズドソース推論能力の独占を打破:Opusレベルの推論能力が初めて27Bスケールでオープンソース形式で出現
- ローカルデプロイのハードルを低減:24GB VRAMで実行可能、绝大多数の個人開発者のハードウェア条件をカバー
- 蒸留技術の検証:クローズドソースのフラッグシップの出力でオープンソースの小型モデルをトレーニングすることが、能力の飛躍的な向上への実現可能なパスであることを証明
どう活用できるか
- ローカル推論テスト:24GB VRAMのGPUをお持ちなら、モデルをダウンロードして直接試してみよう。OllamaやvLLMでのロードが可能
- エージェントフレームワーク統合:Hermes AgentやOpenClawなどのエージェントフレームワークはカスタムモデルエンドポイントに対応しており、このモデルを推論バックエンドとして使用できる
- 比較評価:DeepSeek V4やGLM-5.1などのモデルと同じタスクでベンチマークを走らせ、蒸留効果が期待通りか確認しよう
リスクと制限
蒸留モデルは万能ではない:
- 知識の截止:蒸留モデルのトレーニングデータは当時のOpusの知識ウィンドウに依存する
- ドメインシフト:Opusが得意としない垂直分野では、蒸留効果が低下する可能性がある
- 量子化ロス:4ビット量子化は複雑な推論チェーンの精度に一定の影響を与える。重要なシーンではFP16バージョンの使用を推奨
一言
Qwen3.6-27B蒸留バージョンの登場は、オープンソース推論モデルが「使える」から「使いやすい」への段階を進んでいることを示している——しかもこの「使いやすい」はすでにコンシューマー級GPUのVRAMの中に収まっている。