Conclusion
A 27-billion-parameter open-source model is packaging reasoning capabilities that once belonged exclusively to closed-source flagships into a 4-bit quantized version that fits on consumer-grade GPUs — the appearance of Qwen3.6-27B-Claude-Opus-Reasoning-Distill-v2-int4-AutoRound on Hugging Face has sparked over 4,000 views and 67 bookmarks. The signal behind it is clear: the barrier to entry for open-source reasoning models is being dramatically lowered.
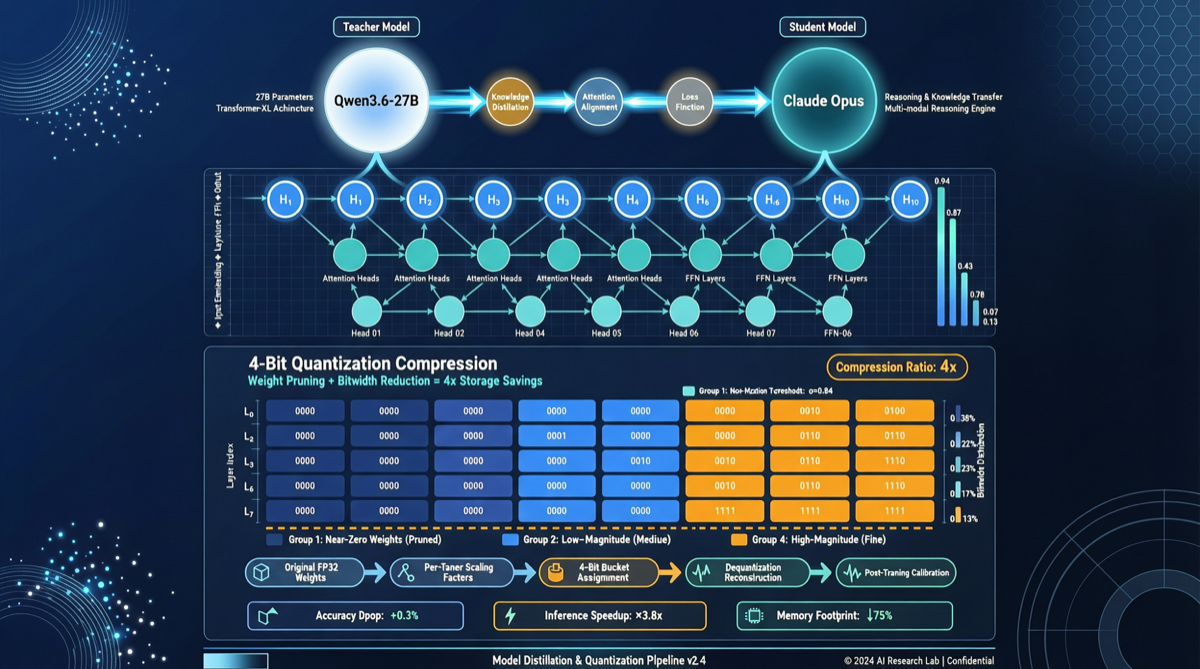
What Exactly Was Distilled
The core idea is straightforward but effective:
- Base model: Qwen3.5 (Alibaba’s Tongyi Qianwen series, reasoning-optimized version), 27B parameters
- Distillation source: Claude Opus (Anthropic’s flagship model) reasoning traces
- Quantization: AutoRound framework’s int4 quantization scheme
Distillation here is not simply “mimicking outputs” — it’s learning Opus’s reasoning paths in complex reasoning tasks: how to break down problems, how to verify step by step, how to express confidence under uncertainty.
The training pipeline roughly works like this:
- Generate a large volume of high-quality reasoning samples using Claude Opus (math reasoning, code reasoning, logic chains)
- Train on Qwen3.5, aligning its hidden states with Opus’s intermediate representations
- Apply 4-bit quantization via AutoRound, compressing to fit within 24GB VRAM
Why 27B + 4-Bit Is the Key Number
This combination is not arbitrary. After 4-bit quantization, a 27B-parameter model requires only about 13-14GB of VRAM for weights. Adding KV cache, a 24GB consumer GPU (RTX 3090/4090) can fully load and run it.
Here’s a comparison of key numbers:
| Model | Parameters | Quantized VRAM | Reasoning Tier |
|---|---|---|---|
| Claude Opus 4 | ~Thousands B | Cannot run locally | Flagship |
| Qwen3.5-72B | 72B | 48GB+ (FP16) | Strong reasoning |
| Qwen3.6-27B-int4 | 27B | ~14GB | Near Opus |
This means: individual developers can now locally run a model with reasoning capabilities approaching Opus — for the first time.
Community Response
The post on X/Twitter garnered 75 likes and 67 bookmarks — a high interaction ratio for AI model posts. Key viewpoints from the comments:
- “This is advanced text and image reasoning compressed into a 4-bit quantized package” — text and image reasoning capabilities compressed into a 4-bit quantized package
- Focus centers on consumer GPU usability and the reasoning quality gap compared to the original Opus
- Some users have already deployed and tested locally, reporting that “performance on math reasoning and code generation tasks exceeded expectations”
Significance for the Chinese Model Ecosystem
The Qwen series has always followed an “open-source + strong reasoning” route. The appearance of this distilled version is significant on several dimensions:
- Breaking closed-source reasoning monopoly: Opus-level reasoning capability appears in open-source form at the 27B scale for the first time
- Lowering local deployment barrier: Running on 24GB VRAM covers the hardware conditions of the vast majority of individual developers
- Distillation technology validation: Proves that training smaller open-source models on closed-source flagship outputs is a viable path for capability leaps
How You Can Use It
- Local inference testing: If you have a 24GB VRAM GPU, download the model and test it directly. Load with Ollama or vLLM
- Agent framework integration: Agent frameworks like Hermes Agent and OpenClaw support custom model endpoints — this model can serve as a reasoning backend
- Comparative evaluation: Run benchmarks against models like DeepSeek V4 and GLM-5.1 on identical tasks to verify whether distillation effects meet expectations
Risks and Limitations
Distilled models are not a silver bullet:
- Knowledge cutoff: The distilled model’s training data depends on Opus’s knowledge window at the time
- Domain shift: In vertical domains where Opus is not strong, distillation effects may degrade
- Quantization loss: 4-bit quantization has some impact on the precision of complex reasoning chains; use the FP16 version for critical scenarios
One Line
The emergence of the Qwen3.6-27B distilled version signals that open-source reasoning models are leaping from “usable” to “good” — and this “good” has already fit into consumer GPU VRAM.