AI Agent 现在有一个很蠢的问题。
你花半小时和一个 Agent 对话,教它你的偏好、你的项目结构、你的代码风格。然后你开了一个新会话——Agent 忘得一干二净。
每次对话都是一次初次见面。
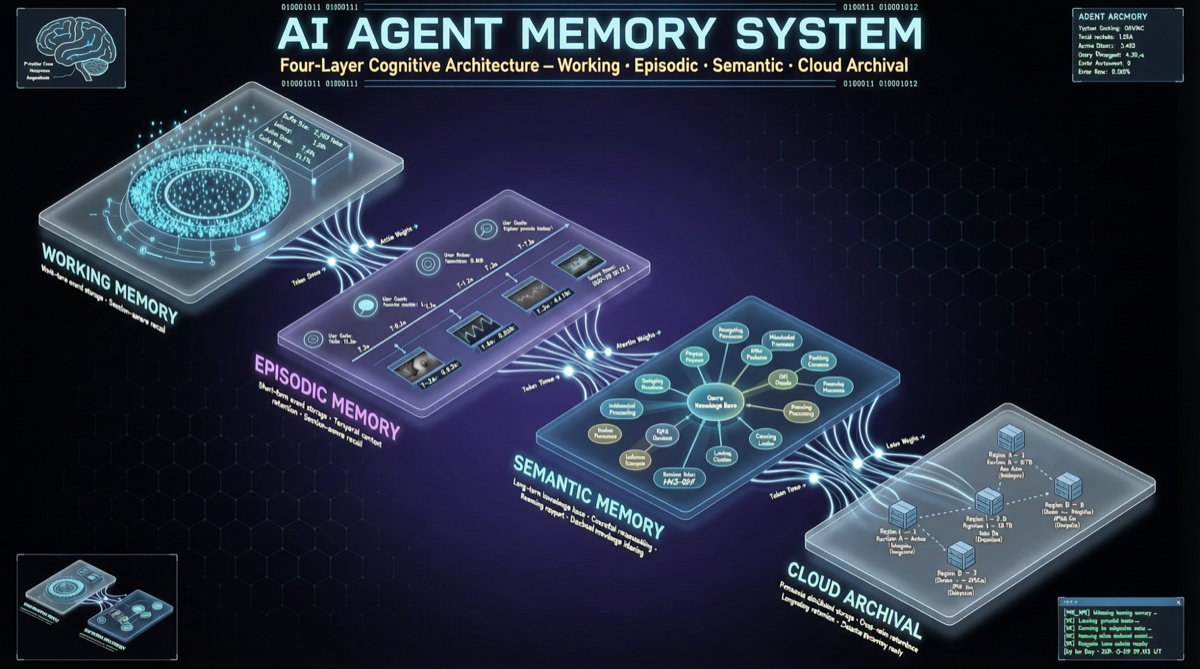
四层记忆架构
有人在尝试解决这个问题,思路是模仿人类的记忆分层:
L1 工作记忆(<5ms):相当于你的短期记忆。当前任务需要的信息,实时读写,速度极快。比如"用户正在编辑哪个文件"。
L2 情景记忆(事件图谱):记录发生过的事情。不是原始日志,而是结构化的事件图——"用户昨天修改了 auth 模块,因为发现了一个 token 过期 bug"。
L3 语义记忆(压缩 HNSW):把经验压缩成可检索的知识。类似你的"常识"——不用记得具体哪天发生了什么,但知道"这个项目的认证用 JWT"。
L4 云端归档 + 身份持久化:长期存储。类似你的日记本——不常翻,但需要的时候能查到。
核心挑战不是存储,而是自适应检索。Agent 需要在 L1 到 L4 之间自动判断"这条信息该去哪里找",而不是每次都要你手动指定。
为什么这是 Agent 基础设施的关键一环
现在 Agent 框架(LangChain、CrewAI、OpenClaw)解决的是"怎么让 Agent 调用工具、执行任务"。但没人很好地解决"怎么让 Agent 记住之前的事"。
结果就是 Agent 的能力被限制在单次会话内。它可能很擅长写代码、查数据、做分析——但它不记得你上周让它做了什么。
如果一个 Agent 不能跨会话记住上下文,它本质上还是一个高级的聊天机器人,不是真正的"工作人员"。
竞争格局
这个方向已经有人在做了:
rohitg00/agentmemory(3.4K 星)——专注于编码 Agent 的持久化记忆,基于基准测试排名- Cloudflare 的 Agent Memory 技术文档——在边缘层面解决记忆存储问题
- 现在这个四层 Memory OS 的思路更系统化,从架构层面设计整个记忆管线
但都还在早期阶段。没有一个是"开箱即用"的生产级方案。
一个现实判断
给 Agent 加持久记忆这件事,技术上不难——难的是怎么决定该记住什么、该忘掉什么。
如果 Agent 记住了一切,检索会变慢,存储成本会飙升,而且大多数记忆是噪音。如果记太少,又回到了"金鱼记忆"的问题。
四层架构的思路是对的——用不同的存储策略匹配不同的记忆类型。但关键参数(什么信息进 L2 而不是 L3、压缩率多少、检索阈值怎么设)目前都是拍脑袋定的。
这个方向值得跟。下次有项目把记忆策略做成可配置的,我会第一时间试用。
→ 延伸阅读:Agent 持久化记忆工具 | Agent 上下文持久化方案
主要来源: