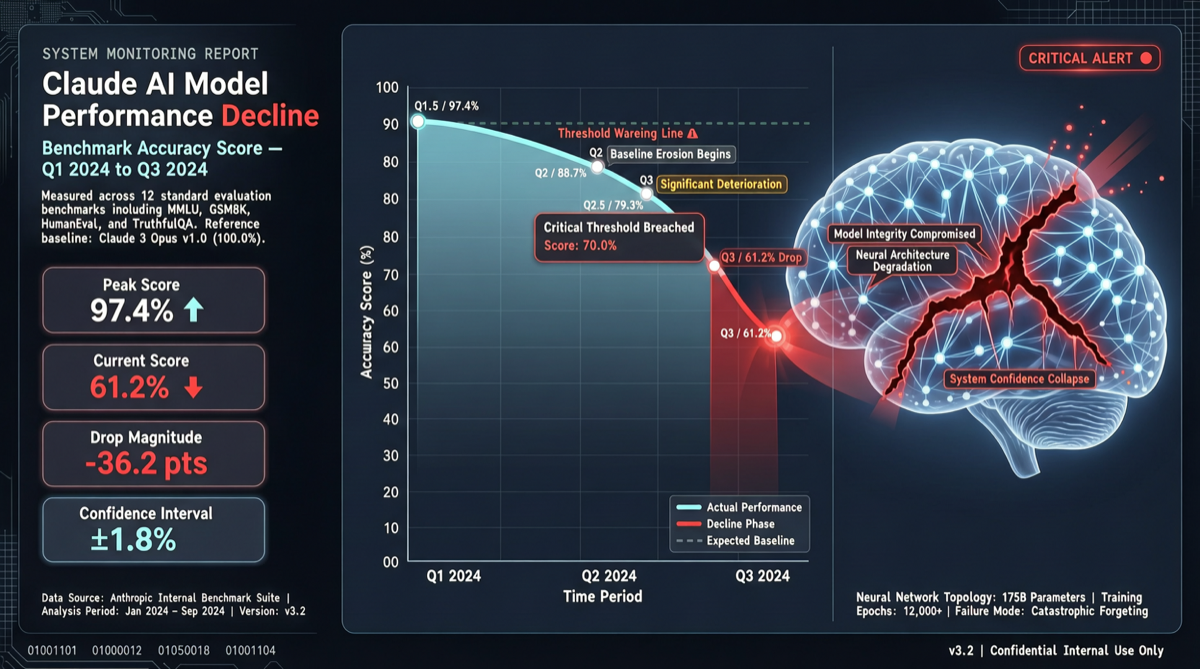
Key Takeaway
Latest hallucination benchmark data shows Claude Opus 4.6 accuracy plummeting from 83.3% to 68.3% in a single week, ranking dropping from #2 globally to #10, falling out of the recognized “elite tier” (top 5).
For users relying on Claude for fact-intensive work (legal, medical, financial analysis, academic research), this is a signal requiring immediate attention.
Data Comparison
| Metric | Last Week | This Week | Change |
|---|---|---|---|
| Accuracy | 83.3% | 68.3% | -15.0% |
| Ranking | #2 | #10 | ↓ 8 positions |
| Tier | Elite | Mainstream | Downgraded |
Possible Causes
1. Benchmark Methodology Update
The most likely explanation is the testing party updated their evaluation methodology:
- Newer trap questions: More subtle “plausible but incorrect” test cases
- Domain expansion: Added previously uncovered domains (latest events, specialized knowledge)
- Stricter scoring: Lower scores for “partially correct” answers
2. Model Drift
Alternatively, the model itself may have changed:
- Silent API update: Anthropic may have deployed a new version backend without notice
- Service degradation: Reduced sampling quality to control inference costs
- Cache strategy changes: Increased cache hit rate at the expense of output quality
3. Dataset Contamination
- Training data mixed with incorrect information
- Biased human feedback introduced during fine-tuning
User Protection Strategies
Short-term
-
Independently verify factual claims
- Cross-check dates, statistics, regulations with search engines or professional databases
- Don’t trust any AI model’s “confident statements” on facts
-
Switch to Opus 4.7
- If available, upgrade to Opus 4.7 (~87% hallucination accuracy)
- Note: Opus 4.7 has been placed behind Anthropic’s Pro paywall
-
Add system prompt constraints
For facts you're uncertain about, explicitly state "I'm not sure" rather than guessing. When providing specific numbers or dates, cite your source.
Long-term
| Work Type | Recommended Model | Reason |
|---|---|---|
| Code Generation | Claude Code / Codex | Code is executable verification |
| Fact Retrieval | GPT-5.5 + Search | Stronger retrieval augmentation |
| Creative Writing | Opus 4.6 still viable | Low hallucination risk |
| Legal/Medical | Multi-model cross-check + human review | High-risk domains shouldn’t rely on single models |