Bottom Line
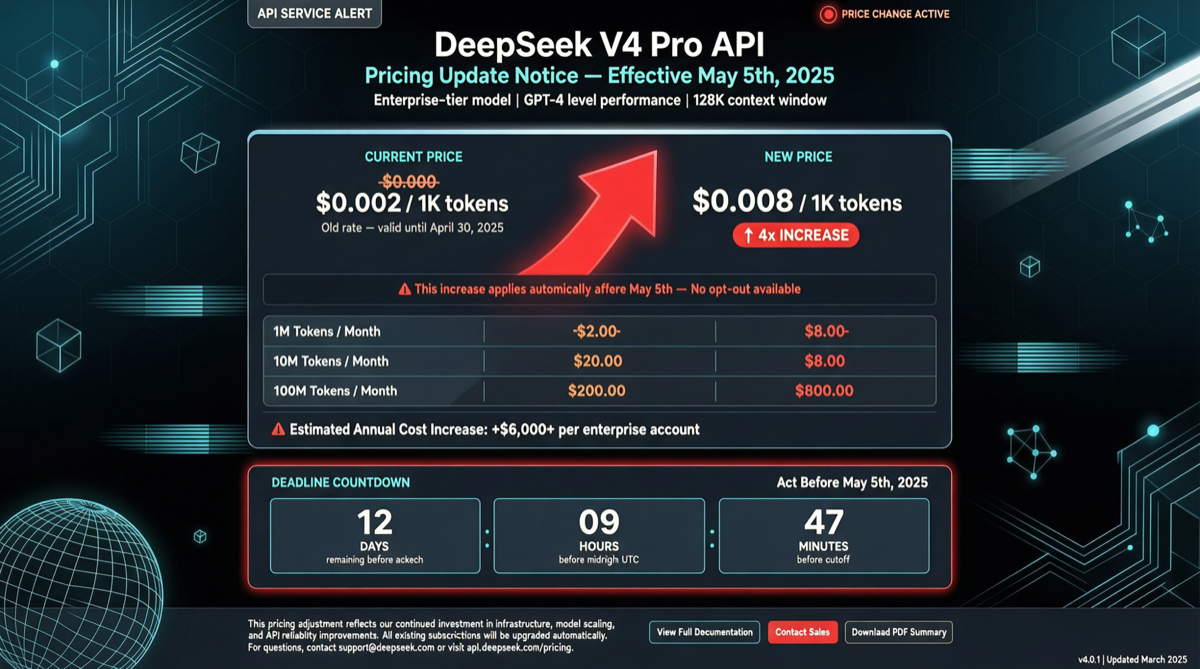
DeepSeek V4 Pro’s limited-time 75% discount will officially end at 15:59 UTC on May 5, 2026 (early morning May 6 Beijing time). When the discount expires, API prices will immediately revert to original levels—a 4x increase.
For users who have configured DeepSeek V4 Pro as a reasoning engine in Claude Code, OpenClaw, OpenCode, or other tools, this means monthly API costs will suddenly balloon. If you rely on the 1M context window for bulk processing, we recommend completing cost assessments and budget adjustments today.
Price Comparison
| Item | Promo Price (until May 5) | Original Price (from May 6) | Increase |
|---|---|---|---|
| Input (cache hit) | $0.109/million tokens | $0.435/million tokens | 4x |
| Input (cache miss) | $0.218/million tokens | $0.87/million tokens | 4x |
| Output | $0.435/million tokens | $1.74/million tokens | 4x |
| Output (priority) | $0.87/million tokens | $3.48/million tokens | 4x |
Real-World Impact on You
Scenario 1: AI Coding Tool Users
If you’ve set deepseek-v4-pro[1m] as your default model in Claude Code or OpenClaw:
- Processing a 500K token codebase analysis costs roughly $0.22 now, rising to $0.87 after May 6
- If your agent runs 10 such tasks per hour, daily cost jumps from $5.28 to $20.88
Scenario 2: Batch Data Processing
Using V4 Pro’s 1M context for document summarization and data extraction:
- Processing 100 documents of 500K tokens daily, monthly cost rises from ~$327 to ~$1,308
Scenario 3: Personal Experimentation/Learning
If you’re only occasionally calling the API for testing, the impact is limited. The absolute cost per call remains low—it’s just returning to normal from the previous “floor price.”
Response Strategies
Immediate Action (before May 5):
- Check your API usage dashboard: Confirm current consumption rate, estimate post-price-increase monthly costs
- Front-load batch tasks: Move remaining bulk processing for the month to before May 5
- Adjust rate limits: If using a prepaid account with a fixed budget, reduce concurrency appropriately to extend quota
Medium-to-Long-term Strategies:
- Cache optimization: DeepSeek’s cache-hit pricing is only 1/4 of cache-miss pricing—ensure repeated contexts use cache keys
- Model downgrade: Switch non-critical scenarios to DeepSeek-V4-Flash or other cheaper open-source models
- Hybrid approach: Use V4 Pro for critical reasoning, Flash or locally-deployed small models for simple tasks
- Monitor alternatives: Qwen3.6-35B-A3B (only activates 3B parameters), MiniMax M3, and other recently open-sourced models are also catching up in performance
Background: Why DeepSeek Uses a Promo Strategy
When DeepSeek V4 Pro launched on April 24, it immediately attracted a large number of developers and enterprises with its 75% OFF limited-time discount. This “low price to acquire users, then restore pricing” strategy is not uncommon in the AI API market—Anthropic and OpenAI have also used similar early-bird discounts for new model launches.
The key difference is that DeepSeek V4 Pro, with its 1.6 trillion parameters and 1M context window, has indeed built a considerable user habit during the promo period. How many users will stay after the May 6 price restoration versus how many will migrate will be an interesting indicator of AI model market loyalty.
Concurrent Fundraising Activity
Another notable piece of news: DeepSeek is currently in a new fundraising round. According to disclosures, only 10 members have left its 270-person research team over the past year—an exceptionally high retention rate. The previous training round cost a few hundred million dollars, while the next generation model’s training cost is estimated at ~$2.5 billion (comparable to GPT-5.5’s training cost).
This means DeepSeek needs to balance model quality and commercial revenue—the pricing restoration after the promo may well be part of preparing funds for the next round of large-scale training.