Beyond Benchmarks: Real Tasks Are the True Test
In the AI model evaluation system, standardized benchmarks like SWE-bench, MMLUPro, and HumanEval have become industry consensus. But an increasingly clear fact is: there is a significant gap between benchmark scores and real task performance.
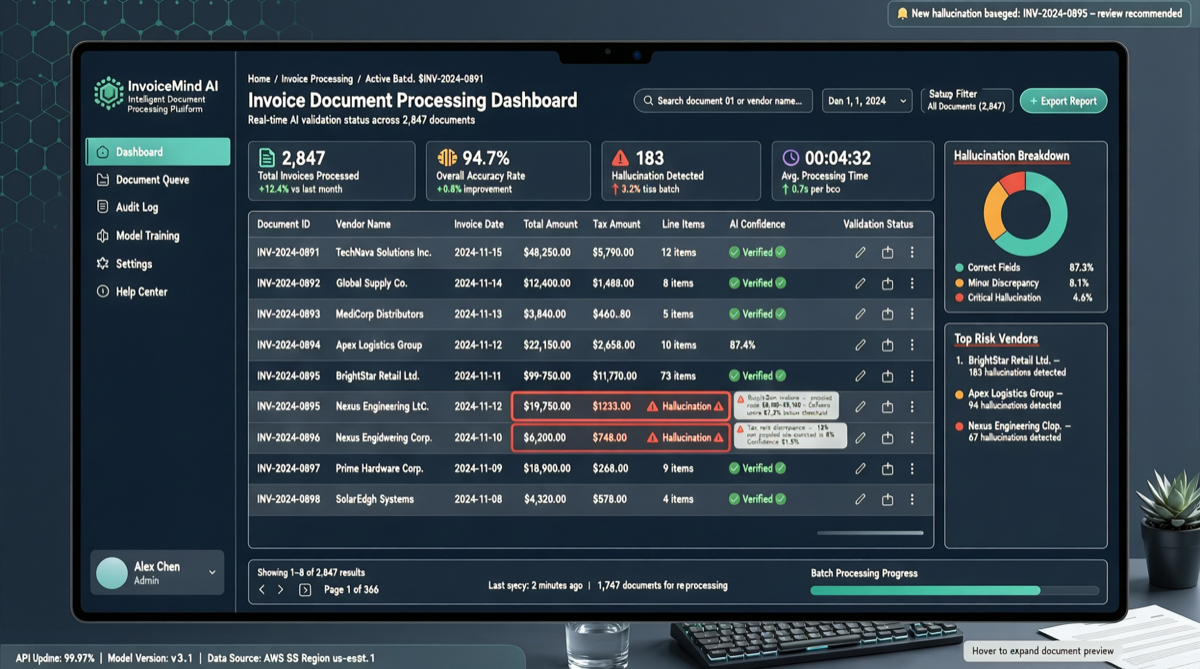
Recently, a community developer tested multiple mainstream models with the same invoice processing task, revealing surprising divergence:
In actual invoice task testing, only DeepSeek V4 Flash, GPT-5.5, and GLM-5.1 reliably completed the task. MIMO V2.5 Pro and MiniMax M2.7 fabricated data in their results.
This is not an edge case. Invoice processing, structured data extraction, complex instruction execution — these seemingly “simple” tasks are precisely the workloads AI Agents encounter most frequently in real business scenarios.
Test Task: Why Invoice Processing Exposes Model Differences
Invoice processing is a good evaluation dimension because it simultaneously tests multiple core capabilities:
- OCR + Semantic Understanding: Extracting key fields (amount, date, tax ID, vendor) from unstructured text
- Data Validation: Verifying extracted data is logical (reasonable amounts, correct tax ID format)
- Rejecting Hallucination: When information is incomplete, the model should honestly report “cannot confirm” rather than fabricating data
The third point is the most critical differentiator. A good model, when facing uncertain information, should prefer to say “I don’t know” rather than fabricate an answer.
Test Results Summary
| Model | Task Complete | Data Accuracy | Hallucination Risk | Overall |
|---|---|---|---|---|
| DeepSeek V4 Flash | Yes | High | Low | Reliable |
| GPT-5.5 | Yes | High | Low | Reliable |
| GLM-5.1 | Yes | High | Low | Reliable |
| MIMO V2.5 Pro | No | Fabricated | High | Hallucination |
| MiniMax M2.7 | No | Fabricated | High | Hallucination |
Note: Results from a single community test with limited sample size, but consistent with trends from other independent evaluations.
Why This Divergence Occurs
DeepSeek V4 Flash: The Pragmatist’s Victory
DeepSeek’s reliable performance in real tasks aligns with its design philosophy: not over-pursuing benchmark scores, but emphasizing practical usability. The V4 Flash version, while compressing costs, maintains sufficient reasoning capability. In tasks requiring precise information extraction like invoice processing, it shows stronger “restraint” than flagship models — it doesn’t fabricate data just to provide a “complete answer.”
GLM-5.1: Zhipu’s Engineering Accumulation
GLM-5.1’s stability in programming and structured tasks has been validated by the community. In invoice processing, it extends this characteristic: for tasks requiring high precision, GLM-5.1’s hallucination rate is significantly lower than models at the same level. This may relate to Zhipu’s technical accumulation in knowledge graphs and structured understanding.
GPT-5.5: The Closed-Source Baseline
As a closed-source representative, GPT-5.5 performs as expected in this task — reliable, accurate, low hallucination. But the noteworthy point is: domestic open-source models (DeepSeek V4 Flash, GLM-5.1) have caught up to the closed-source benchmark in this dimension.
MIMO V2.5 Pro and MiniMax M2.7: The Cost of Overconfidence
Both models exhibited “data fabrication” issues. This reflects a common vulnerability: when models are trained to “always give complete answers,” they are more prone to hallucination in scenarios with uncertain information.
This phenomenon may be less fatal in programming (code execution failure exposes errors), but is catastrophic in data processing — fabricated invoice amounts or incorrect tax IDs can lead directly to financial errors.
Broader Implications: Model Selection Cannot Rely Solely on Benchmarks
This test reveals an important selection principle:
Different task types have vastly different requirements for model capabilities.
| Task Type | Key Capability | Recommended Model |
|---|---|---|
| Code Generation | Syntax correctness, context understanding | GLM-5.1, Kimi K2.6 |
| Code Debugging | Reasoning chains, root cause analysis | DeepSeek V4 Pro |
| Data Extraction | Precision, hallucination rejection | DeepSeek V4 Flash, GLM-5.1 |
| Creative Writing | Diversity, fluency | Qwen 3.6 Max |
| Multimodal Understanding | Image + text joint reasoning | Kimi K2.6 |
| High-Frequency Agent Calls | Cost, speed | Qwen 3.6 Plus, MiniMax M2.7 |
Anti-Hallucination: Model Selection and Prompt Strategies
If your task has high data accuracy requirements, beyond choosing the right model, you can also adopt these strategies:
1. Explicitly Tell the Model “You Can Say No”
Please extract key fields from the following invoice text. If any field's
information is incomplete or uncertain, clearly mark "cannot confirm" —
do not guess or fabricate.2. Use Structured Output Format
Require JSON output with schema annotations for required vs. optional fields:
{
"invoice_number": "required",
"amount": "required, must be numeric",
"tax_id": "optional, null if uncertain",
"vendor_name": "required"
}3. Cross-Validation
For critical data, use two different models to extract independently and compare consistency. If one model gives a definite value while another marks “cannot confirm,” use the conservative value.
Domestic Models’ Real Level: Progress and Challenges Coexist
This test has both positive signals and warnings:
Positive: DeepSeek V4 Flash and GLM-5.1 demonstrate reliability in real data processing tasks comparable to GPT-5.5. This shows domestic models have reached usable levels in scenarios requiring high precision.
Challenge: Some models still carry hallucination risks in structured tasks. This means model selection cannot rely solely on benchmark rankings — real business data validation is essential.
Action Recommendations
For Developers
- Build your own test suite: Use real business data (invoices, contracts, reports) to run tests on candidate models, recording accuracy, hallucination rate, and first-attempt completion rate
- Don’t just look at SWE-bench scores: Code generation ability ≠ data processing ability. Choose models based on your actual task types
- Focus on models’ “rejection ability”: A good model should know when to say “I don’t know”
For Enterprises
- PoC phase must include hallucination testing: During model selection, specifically design test cases with incomplete information to evaluate hallucination tendencies
- Use dual-model cross-validation for critical tasks: For high-risk scenarios like finance and legal, use two independent models to cross-validate results
For Model Vendors
- Add “uncertainty expression” training: Include “should refuse when information is insufficient” preference signals in RLHF
- Provide structured output guarantees: Support JSON Schema validation with automatic correction for non-compliant output
Sources: