Если вы запускаете локальные LLM на Mac, то наверняка слышали об Ollama. Он действительно удобен — одна команда для запуска, полная библиотека моделей. Но если вас волнует только одно — скорость, то Ollama может быть не лучшим выбором.
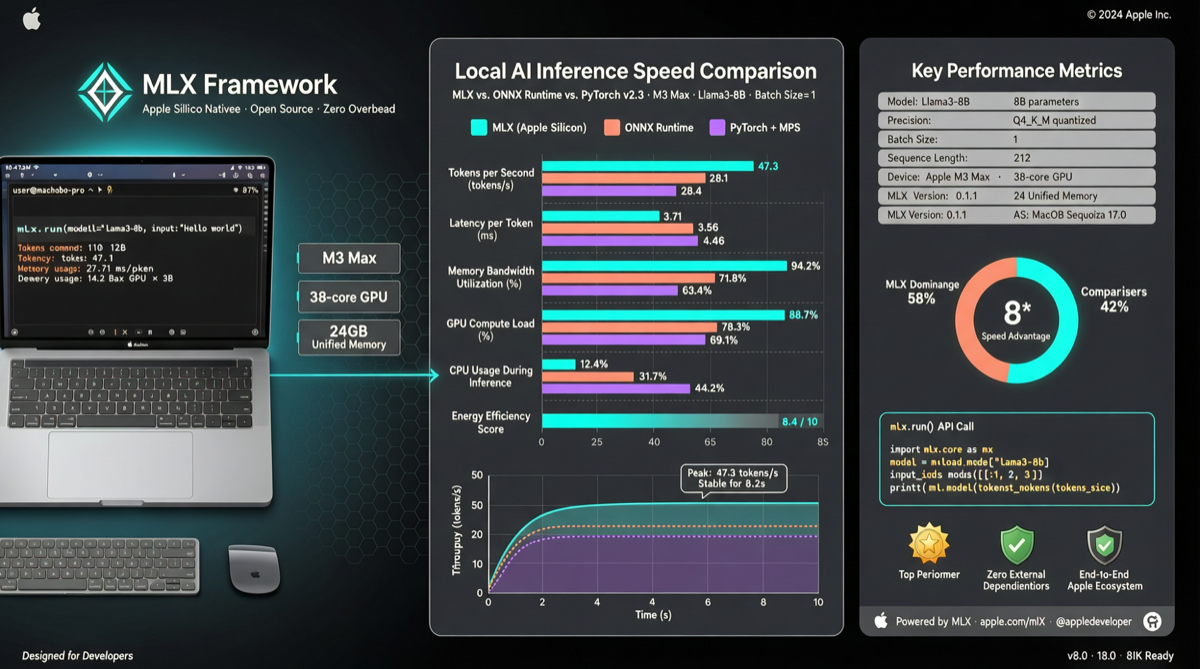
Rapid-MLX набирает популярность в китайском сообществе разработчиков. Главное преимущество простое: на Apple Silicon он работает в 2-4 раза быстрее Ollama. Не за счёт подкрутки параметров, а благодаря архитектурной оптимизации, которая по-настоящему понимает чипы M-серии.
За счёт чего достигается скорость
Rapid-MLX использует собственный фреймворк Apple MLX с нативными вычислениями на Metal GPU, напрямую задействуя унифицированную архитектуру памяти Apple Silicon. Это не сторонний хак — это реализация на родном технологическом стеке Apple.
Реальные цифры:
При запуске Qwen3.5-9B, Rapid-MLX выдаёт 108 tok/s против 41 tok/s у Ollama — разница в 2.6 раза. На 4B моделях достигает 160 tok/s.
Для плотных моделей вроде Qwen3.6-27B — 36.5 tok/s при потреблении 14.9GB памяти, полная поддержка coding-сценариев. MoE-версия на 35B достигает 92 tok/s, используя всего 19GB, на 12% быстрее версии 3.5.
DeepSeek V4 Flash также поддержан с первого дня — MoE-архитектура 158B-A13B с контекстом 1M работает на 56 tok/s на Mac Studio с 2-битной квантованием.
Не только скорость
Скорость — это входной билет, но Rapid-MLX умеет больше, чем просто вывод.
Он предоставляет API, совместимый с OpenAI, что означает — ваш существующий код практически не требует изменений. Инструменты вроде Cursor, Claude Code и Aider подключаются напрямую. Встроен 17 парсеров инструментов, нативная поддержка вызова инструментов. Есть кэширование промптов, cached TTFT снижен до 0.08 секунд.
Одна команда для запуска:
pip install -U rapid-mlx
rapid-mlx serve qwen3.6-27b
Или через Homebrew:
brew install raullenchai/rapid-mlx/rapid-mlx
rapid-mlx serve qwen3.5-4b
После запуска на порту 8000 доступен OpenAI-совместимый API со встроенной документацией Swagger UI.
Но не спешите выбрасывать Ollama
Высокая скорость не означает полное превосходство. Текущие слабости Rapid-MLX очевидны.
Узкая поддержка моделей. Работает только на Apple Silicon. Ollama поддерживает Mac, Linux и Windows. Если кто-то в вашей команде использует Windows, Rapid-MLX отпадает.
Размер библиотеки моделей. Библиотека Ollama покрывает практически все основные модели с открытым исходным кодом. Day-0 поддержка у Rapid-MLX хороша, но для длинного хвоста моделей потребуется время.
Экосистема сообщества. У Ollama огромное сообщество, туториалы, интеграции. У Rapid-MLX — 1.9k звёзд и 467 коммитов, проект还在快速迭代中.
Моя оценка: если вы используете Mac для локального вывода и больше всего цените скорость и опыт вызова инструментов, Rapid-MLX стоит попробовать. Особенно для моделей Qwen и DeepSeek — оптимизация специально нацелена на них. Но если нужна кроссплатформенность, разнообразие моделей или зависимость от экосистемы — Ollama остаётся более надёжным выбором.
Они не исключают друг друга. В моём рабочем процессе я использую Rapid-MLX для локальной разработки с основными моделями, а Ollama — для тестирования и совместной работы.
Что наблюдать дальше
Частота коммитов Rapid-MLX высокая — 467 коммитов, активный трекер задач. Если в ближайшие месяцы удастся расширить поддержку моделей и добавить совместимость с Windows/Linux, есть реальный шанс перейти от «более быстрой опции на Mac» к «основному варианту локального вывода».
Две вещи, на которые я обращу внимание в следующем крупном релизе: приземление SuffixDecoding tier classification framework и сможет ли стабильность вызова инструментов подняться ещё на уровень.
Основные источники: