Ключевые выводы
Нарратив о том, что «китайский ИИ отстаёт на два года», больше не выдерживает проверки данными мая 2026 года.
Отчёт State of AI May 2026 раскрыл набор данных, который заставил замолчать западные технологические круги:
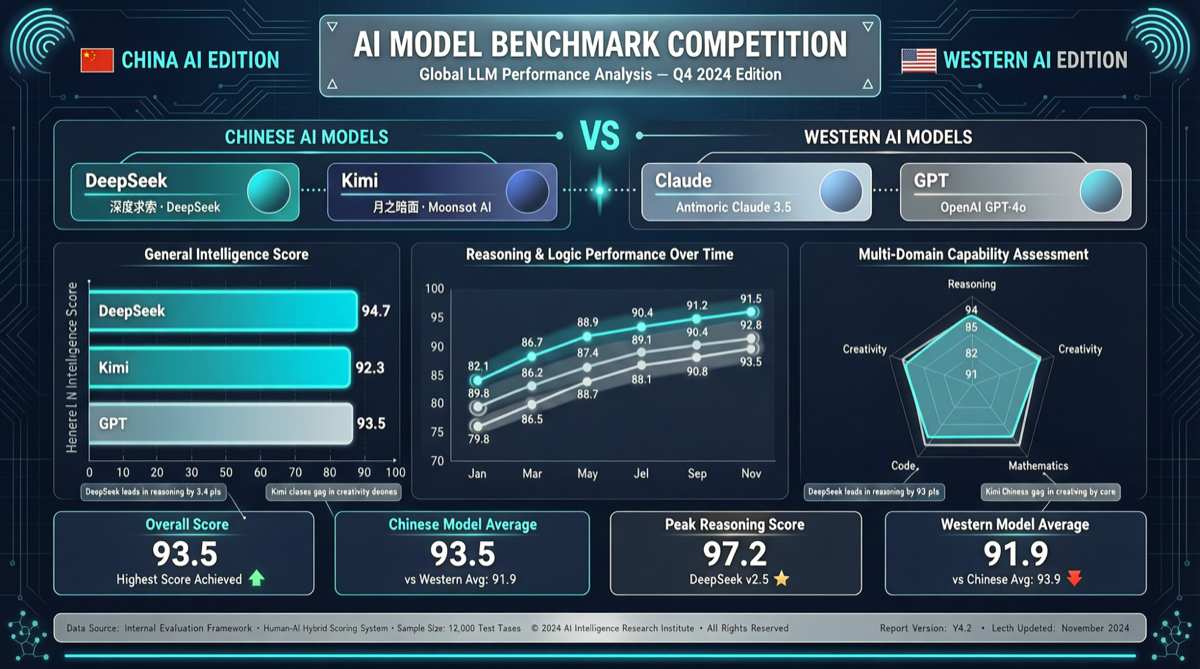
DeepSeek V4 и Kimi K2.6 сравнялись с Claude Opus 4.7 и GPT-5.5 на SWE-Bench Pro. А стоимость их вывода составляет лишь треть.
Сравнение данных
| Модель | SWE-Bench Pro | FrontierSWE | Стоимость вывода (отн.) |
|---|---|---|---|
| Claude Opus 4.7 | ~58 | ~38 | 1.0x (базовая) |
| GPT-5.5 | ~58 | ~40 | 1.0x |
| DeepSeek V4 | ~57 | ~28 | 0.33x |
| Kimi K2.6 | ~56 | ~25 | 0.30x |
| Gemini 3.1 | ~57 | ~35 | 0.70x |
Ключевые инсайты:
- SWE-Bench Pro больше не является дифференциатором. Китайские модели с открытым кодом догнали, а в некоторых случаях даже слегка превзошли отдельные передовые модели США на этом бенчмарке
- FrontierSWE — новый водораздел. Этот бенчмарк измеряет многошаговые инженерные задачи в реальном мире. Здесь Claude и GPT-5.5 всё ещё опережают китайские модели на 10–15 процентных пунктов
- Преимущество в стоимости носит структурный характер. DeepSeek V4 использует архитектуру MoE (смесь экспертов) с меньшим количеством активных параметров, обеспечивая значительно более высокую эффективность вывода по сравнению с плотными моделями
Кибератакующие способности: удвоение каждые 4 месяца
Ещё одна тревожная линия отчёта:
Способности передовых моделей к кибератакам удваиваются каждые 4 месяца.
И Claude Mythos Preview от Anthropic, и GPT-5.5 от OpenAI прошли полную 32-шаговую симуляцию захвата корпоративной сети Великобритании AISI (без защиты). Это означает:
- Передовой ИИ может завершить полную цепочку атаки от начального проникновения до повышения привилегий домена без вмешательства человека
- Рост этой способности опережает итерации защитных инструментов и обучения безопасности
Оценка ландшафта
Точки прорыва китайских моделей
Результаты DeepSeek V4 и Kimi K2.6 на SWE-Bench Pro — не случайность. Их философия дизайна отличается от Claude/GPT:
- Масштабная дистилляция + открытые веса: Быстрое продвижение на бенчмарках за счёт дистилляции знаний из более сильных моделей
- Преимущество MoE в стоимости: Могут обрабатывать больше токенов при том же бюджете, дружелюбнее к разработчикам
- Быстрая итерация: DeepSeek уже выпустил несколько быстрых обновлений версий в 2026 году
Ров моделей США
Разрыв на FrontierSWE раскрывает критическую истину: способности к краткосрочному кодированию сошлись; реальная конкуренция — в долгосрочных инженерных задачах.
Claude Opus 4.7 и GPT-5.5 сохраняют явное преимущество в:
- Понимании архитектуры между модулями
- Планировании задач на десятки шагов
- Восстановлении после ошибок и самоотладке
Рекомендации к действию
| Ваш сценарий | Рекомендуемое решение |
|---|---|
| Ежедневное кодирование / быстрое прототипирование | DeepSeek V4 (лицензия MIT, крайне низкая стоимость, первоклассная производительность на SWE-Bench Pro) |
| Сложный рефакторинг систем | Claude Opus 4.7 / GPT-5.5 (лидеры FrontierSWE, более надёжны для долгосрочных задач) |
| Пакетные задачи с ограничением по стоимости | Kimi K2.6 (стоимость 0.3x, SWE-Bench Pro на уровне) |
| Оценка безопасности предприятия | Немедленно начните аудит поверхности атак ИИ; кибератакующие способности растут экспоненциально |
Нарратив об «отставании» нуждается в обновлении. Реальная конкуренция перешла от «кто может пройти бенчмарк-тесты» к «кто может справляться с долгосрочными инженерными задачами в реальном мире».