核心结论
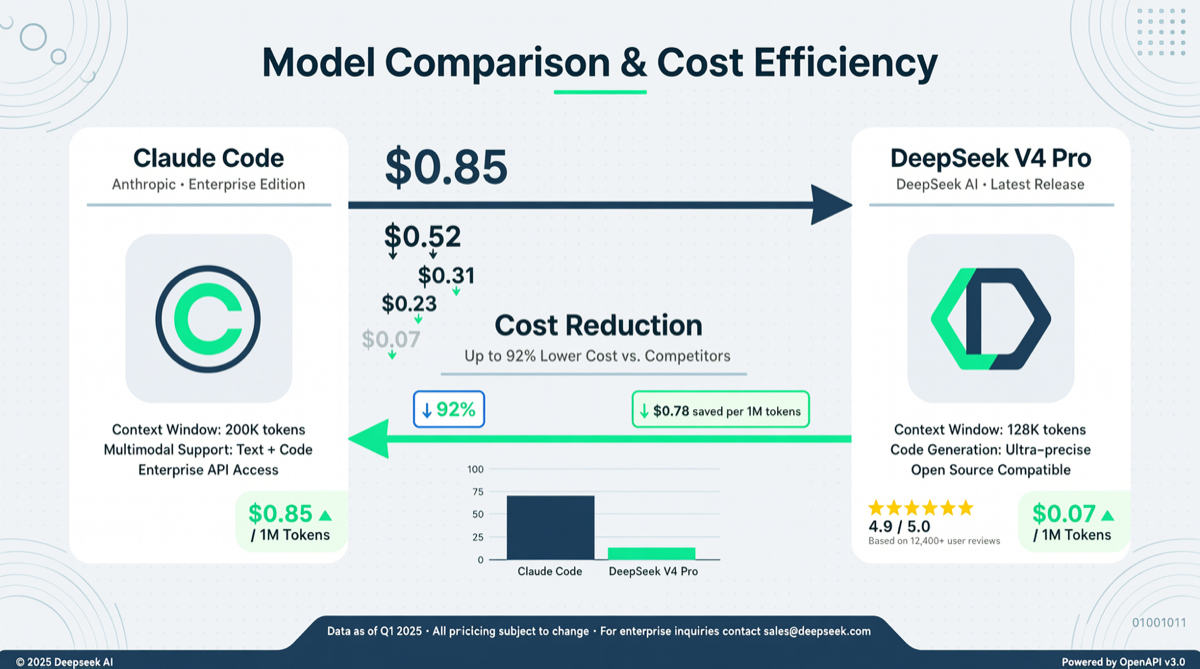
DeepClaude 在 GitHub 上快速走红(HN 124 分、57 讨论),它的核心思路很简单但有效:把 agent loop 拆成 planning + execution 两层,用便宜的 DeepSeek V4 Pro 做规划和推理,Claude Code 专注代码执行。结果是整体成本降到纯 Claude Code 方案的 1/17。
这不仅仅是省钱——它直接回应了 OpenAI 联合创始人 Brockman 关于”算力稀缺”的论断:不是非此即彼,而是聪明的模型做核心决策,便宜的模型干体力活。
价格对比:三层方案实测
| 方案 | 规划模型 | 执行模型 | 单次 agent loop 成本 | 相对成本 |
|---|---|---|---|---|
| 纯 Claude Code | Opus 4.6 | Opus 4.6 | ~$17.00 | 17x |
| DeepClaude | V4 Pro | Claude Code | ~$1.00 | 1x |
| 纯 DeepSeek V4 Pro | V4 Pro | V4 Pro | ~$3.48 | 3.5x |
关键数据点:
- DeepSeek V4 Pro 折扣价:输入缓存命中 $0.04/1M tokens,输出 $0.83/1M tokens(75% OFF 延长至 5 月 31 日)
- Claude Opus 4.6:$15/1M 输入,$75/1M 输出
- DeepClaude 的拆分策略让 90% 的 token 消耗落在 DeepSeek 侧,仅关键代码执行环节走 Claude
架构拆解
DeepClaude 不是简单的模型切换器,它做了三件事:
- 任务分解层:DeepSeek V4 Pro 接收用户需求,拆解为可执行的子任务序列
- 调度层:根据子任务类型动态选择模型——逻辑推理/代码生成走 Claude Code,信息检索/文档总结走 DeepSeek
- 结果聚合层:将多模型输出整合为统一的工作流结果
这种分层架构的启示是:2026 年能赚钱的独立开发者,不是选贵的或便宜的,是知道什么时候该用哪个模型。
实际表现
社区实测反馈:
- 学术海报生成:DeepSeek V4 + OpenClaw 端到端输出,绘图用 GPT Image 2,整体成本不到 $2
- 日常编程任务:能干基本活,debug 场景仍建议切回 Claude Code
- Agent loop 场景(多轮工具调用):成本优势最明显,17 倍差距在此拉开
格局判断
DeepClaude 的走红标志着 AI 工具链进入组合架构时代:
- 模型本身的差距在缩小(DeepSeek V4 Pro 已接近 Opus 4.6 非思考模式水平)
- 真正的护城河是数据、工作流和分发
- “前端大模型 + 后端小模型”的混合架构将成为标配
行动建议
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 简单问答/检索 | 纯 DeepSeek V4 Pro | 成本最低,质量够用 |
| 复杂编码/重构 | DeepClaude | 规划便宜,执行精准 |
| 全量 agent loop | DeepClaude | 17 倍成本差距 |
| 极限 debug | 纯 Claude Code | 执行质量优先 |
上手方式:将 Claude Code 的 model 设置为 deepseek-v4-pro 即可解锁 1M 上下文(需 OpenCode v1.14.24+ 或 OpenClaw v2026.4.24+)。折扣价 5 月 31 日到期,建议趁低价测试工作流。