Core Conclusion
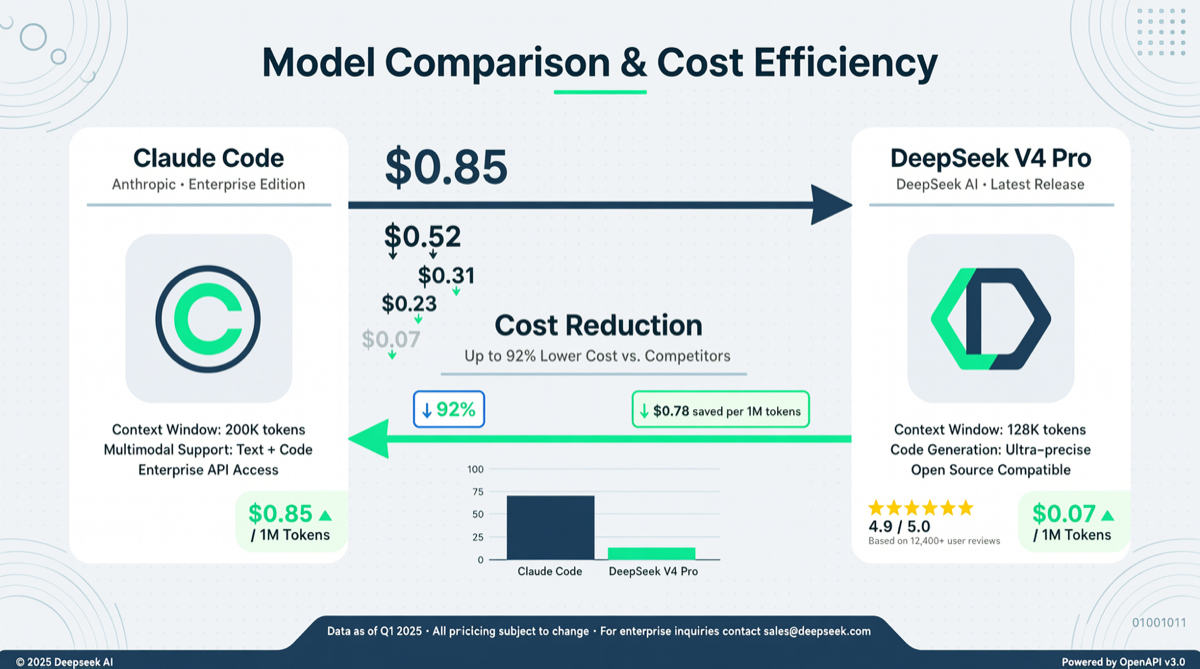
DeepClaude is rapidly gaining traction on GitHub (HN 124 points, 57 discussions). Its core idea is simple but effective: split the agent loop into planning + execution layers, using the cheaper DeepSeek V4 Pro for planning and reasoning while Claude Code focuses on code execution. The result: overall cost drops to 1/17 of a pure Claude Code solution.
This isn’t just about saving money—it directly answers OpenAI co-founder Brockman’s claim about “compute scarcity”: it’s not either-or, but rather smart models make core decisions, cheap models do the heavy lifting.
Price Comparison: Three-Tier Benchmark
| Approach | Planning Model | Execution Model | Cost per Agent Loop | Relative Cost |
|---|---|---|---|---|
| Pure Claude Code | Opus 4.6 | Opus 4.6 | ~$17.00 | 17x |
| DeepClaude | V4 Pro | Claude Code | ~$1.00 | 1x |
| Pure DeepSeek V4 Pro | V4 Pro | V4 Pro | ~$3.48 | 3.5x |
Key data points:
- DeepSeek V4 Pro discounted price: input cache hit $0.04/1M tokens, output $0.83/1M tokens (75% OFF extended to May 31)
- Claude Opus 4.6: $15/1M input, $75/1M output
- DeepClaude’s split strategy puts 90% of token consumption on the DeepSeek side, with only critical code execution routed through Claude
Architecture Breakdown
DeepClaude is not a simple model switcher—it does three things:
- Task Decomposition Layer: DeepSeek V4 Pro receives user requests and breaks them into executable sub-task sequences
- Scheduling Layer: Dynamically selects models based on sub-task type—logic reasoning/code generation goes to Claude Code, information retrieval/document summarization goes to DeepSeek
- Result Aggregation Layer: Integrates multi-model outputs into unified workflow results
The key insight of this layered architecture is: independent developers who make money in 2026 aren’t choosing expensive or cheap—they know when to use which model.
Real-World Performance
Community testing feedback:
- Academic poster generation: DeepSeek V4 + OpenClaw end-to-end output, drawing with GPT Image 2, total cost under $2
- Daily coding tasks: handles basic work, but debugging scenarios still recommend switching back to Claude Code
- Agent loop scenarios (multi-round tool calls): cost advantage is most pronounced—the 17x gap opens up here
Market Positioning
DeepClaude’s rise marks the entry of AI toolchains into the composable architecture era:
- The gap between models is narrowing (DeepSeek V4 Pro is already close to Opus 4.6 non-thinking mode)
- The real moat is data, workflows, and distribution
- “Frontend large model + backend small model” hybrid architecture will become the standard
Action Recommendations
| Scenario | Recommended Approach | Why |
|---|---|---|
| Simple Q&A / retrieval | Pure DeepSeek V4 Pro | Lowest cost, sufficient quality |
| Complex coding / refactoring | DeepClaude | Cheap planning, precise execution |
| Full agent loops | DeepClaude | 17x cost difference |
| Extreme debugging | Pure Claude Code | Execution quality first |
Getting started: Set Claude Code’s model to deepseek-v4-pro to unlock 1M context (requires OpenCode v1.14.24+ or OpenClaw v2026.4.24+). The discounted price expires May 31—test your workflows while it’s cheap.