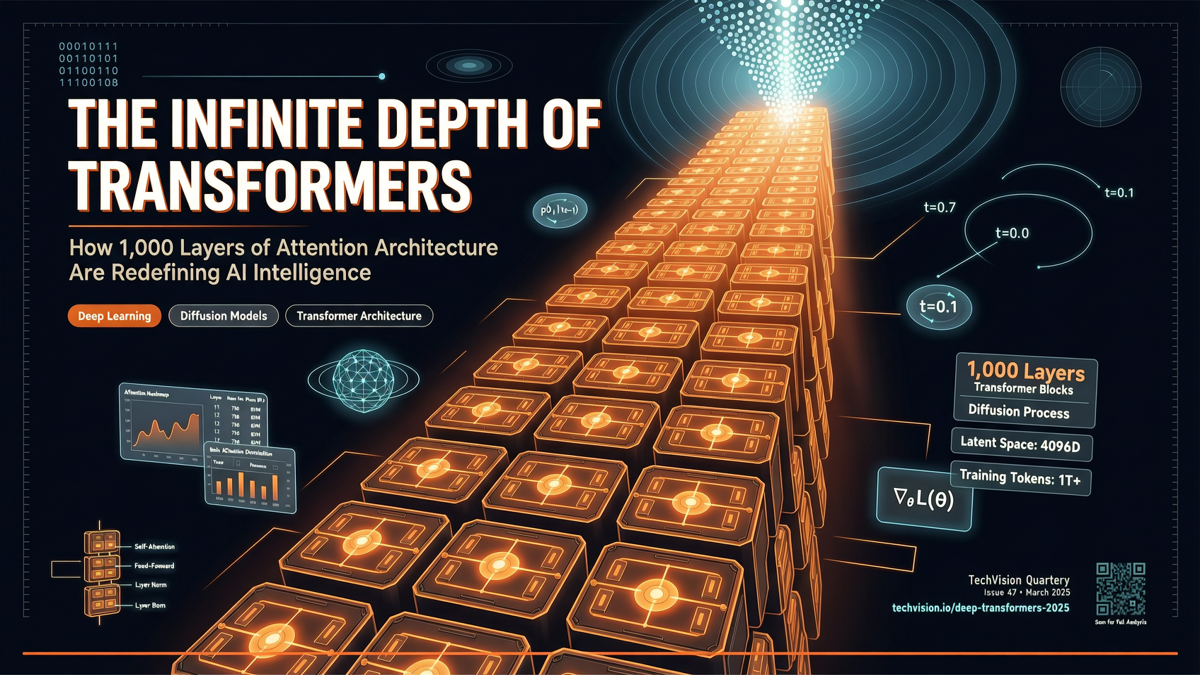
论文标题叫 "Mean Mode Screaming: Mean--Variance Split Residuals for 1000-Layer Diffusion Transformers"。
101 upvotes,当天 Hugging Face Daily Papers 第一名。
标题看着有点无厘头——"Mean Mode Screaming"(均值模式尖叫?)——但背后的技术思路其实很严肃:怎么把 Diffusion Transformer 的层数从常见的 28-64 层,推到 1000 层,而不让模型训练崩溃。
为什么 Diffusion Transformer 很难做深
Transformer 架构在 LLM 里做到 100 多层是家常便饭。但在 Diffusion Model 里,层数通常只有 28 到 64 层。
原因有两个:
第一,梯度消失/爆炸。 Diffusion Model 的训练过程本身就比 LLM 更不稳定。它需要在多个时间步上计算 loss,梯度需要穿过整个去噪过程。层数越多,梯度传播的路径越长,问题越严重。
第二,残差连接不够用。 标准 Transformer 用 residual connection 来缓解深层网络的训练问题,但在 diffusion 场景下,传统的残差连接效果有限。
这就导致了一个尴尬的局面:LLM 的 Transformer 可以随便加层,但 DiT(Diffusion Transformer)的层数一直上不去。
Mean-Variance Split Residuals 是什么
论文的核心创新是一种新的残差连接方式:均值-方差分裂残差。
传统残差连接的公式是:y = x + F(x)。输入直接加到变换后的结果上。
Mean-Variance Split 的做法是:把特征通道拆成两组,一组负责学习均值(mean mode),一组负责学习方差(variance mode)。两组分别做残差连接,然后再合并。
这个设计的直觉是:在深度网络中,均值信号和方差信号的传播特性不同。 均值信号容易在深层网络中衰减(梯度消失),方差信号则容易累积(梯度爆炸)。把两者分开处理,可以分别优化各自的传播路径。
1000 层意味着什么
从 64 层到 1000 层,不只是"层数更多"这么简单。
层数增加 15 倍以上,模型的表达能力理论上会指数级增长。但关键是:能不能有效训练出来?
论文的标题用 "Screaming" 这个词,大概是在暗示:当层数推到极限时,模型的行为会变得极端——要么极好,要么彻底崩溃。而 mean-variance split residuals 的作用就是让模型"尖叫"而不是"沉默"——保持信号在深层网络中的活性。
跟 LLM 的深度对比
这里有一个有意思的对比:
- LLM(GPT-4 等):通常 100 层左右
- DiT(Stable Diffusion 3 等):通常 28-64 层
- 这篇论文:1000 层 DiT
如果 1000 层 DiT 真的能稳定训练且效果优于浅层模型,那意味着 diffusion model 的缩放定律(Scaling Law)可能还有很大的空间没被探索。
但需要注意一个关键区别:LLM 的深度和 DiT 的深度不是同一个概念。 LLM 每层处理的是 sequence 上的自注意力,而 DiT 每层处理的是空间 patch 上的注意力。两者的计算复杂度和信息密度不同。
实际的疑问
101 upvotes 说明社区对这个方向很感兴趣,但有几个问题需要验证:
生成质量是否真的随深度单调提升? 很多架构创新在论文里看起来好,但在实际 benchmark 上提升有限。需要看 FID、IS 等指标。
推理成本增加多少? 1000 层的推理延迟和 64 层差了一个数量级。即使训练出来了,实际部署的成本能不能接受?
有没有消融实验证明 mean-variance split 是关键? 也许 1000 层能跑通主要靠的是其他技巧(比如更好的初始化、学习率调度),而不是这个特定的残差设计。
判断
这是一个勇敢的架构探索。把 DiT 推到 1000 层,不管最终能不能成为主流方案,都能帮助社区理解 diffusion model 的缩放边界在哪里。
如果 mean-variance split residuals 的思路成立,它可能不仅适用于 DiT,还能迁移到其他需要极深层网络的场景。
值得持续跟踪。
主要来源:
- Hugging Face Daily Papers - May 11, 2026
- "Mean Mode Screaming: Mean--Variance Split Residuals for 1000-Layer Diffusion Transformers"