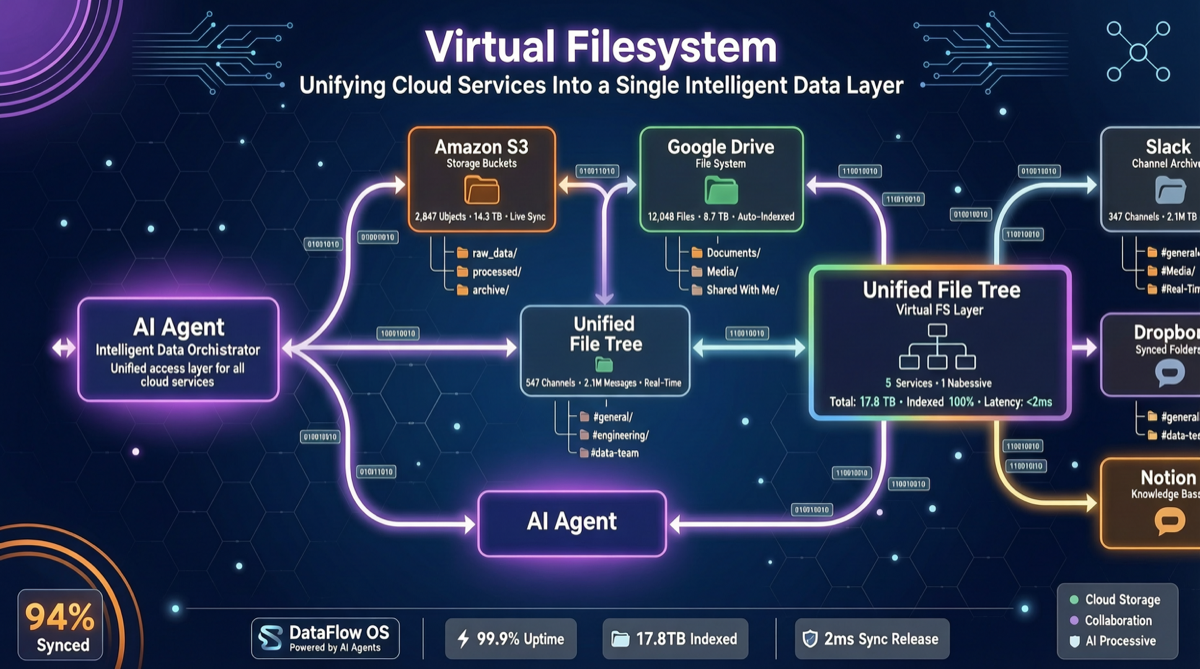
给 Agent 用的虚拟文件系统最近冒出来一堆,但 Mirage 的思路不太一样。
大多数这类项目的做法是给 Agent 封装一套专门的 API 或者 tool——"你想访问 S3 就调这个函数,想读 Google Drive 就调那个"。Mirage 反过来:把所有后端挂到同一棵虚拟文件树下,Agent 只需要会用 ls、cat、grep、cp 这些 bash 命令就行。
怎么做到的
Mirage 通过 FUSE(用户态文件系统)在本地挂载一个虚拟文件系统。你可以在这个文件系统下看到 S3 bucket 里的文件、Google Drive 的文档、Slack 频道的消息、Redis 里的键值对——全部以文件的形式呈现。
对 Agent 来说,数据源之间的差异消失了。它不需要知道"这个文件在 S3 上"还是"这个消息在 Slack 里"——它只需要像操作本地文件一样操作它们。
支持的挂载目标包括:
- S3
- Google Drive
- Slack
- Gmail
- Redis
- 以及更多
为什么这个思路有意思
Agent 最大的弱点之一是工具调用的学习成本。每接一个新的数据源,就要定义新的 tool schema、写新的 prompt 告诉 Agent 怎么用、处理新的错误情况。
Mirage 把这个成本压到零——只要挂上去,Agent 就会用。因为 bash 命令是 Agent 已经掌握的通用技能。
这也是为什么中文社区有人评价"这个一下思路就开阔了,文件系统变成了资源中心"。
但还是很早期
项目昨天刚发布 v0.0.1-alpha.1,只有 4 个 commits,1k stars。Python 和 TypeScript 两个版本的 SDK 都在早期阶段。
alpha 版本意味着什么?意味着你不该在生产环境用它。但它验证了一个值得跟的方向:让 Agent 用最熟悉的方式操作最陌生的数据源。
跟其他 VFS 项目比
同一时间还有几个类似的虚拟文件系统项目在冒头。Mirage 的差异点在于它支持的挂载目标比较多,而且同时提供了 Python 和 TypeScript 的实现。
如果你正在给 Agent 设计数据访问层,Mirage 的思路值得参考——不是封装更多 API,而是降低 Agent 需要学习的接口种类。
主要来源: