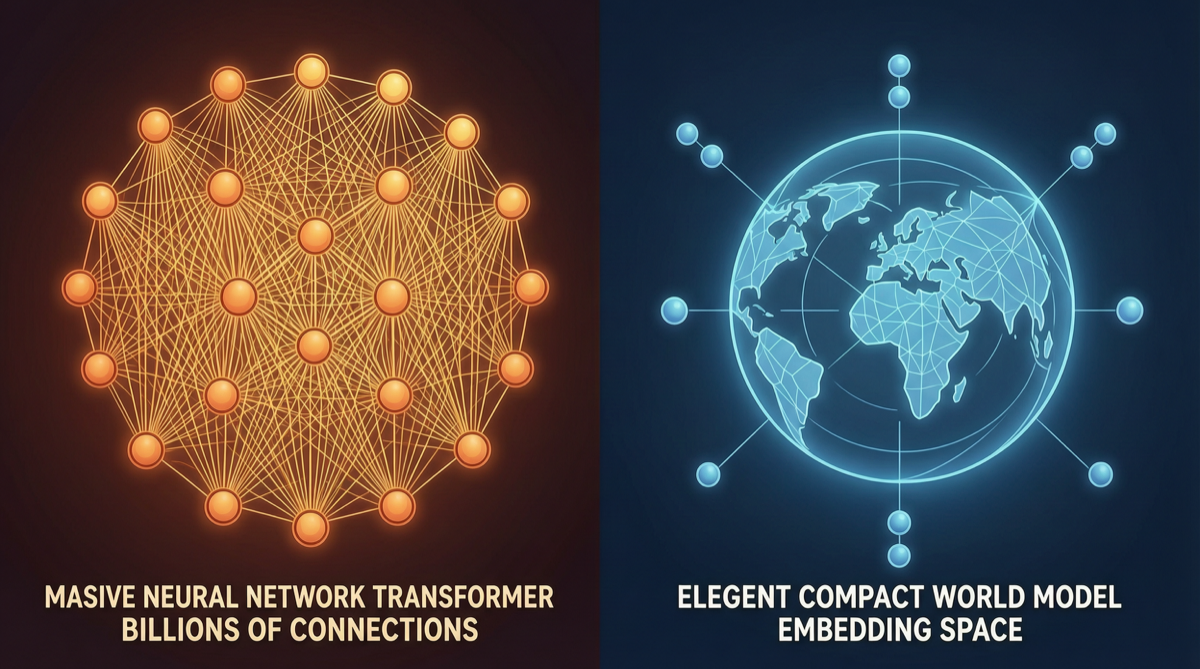
Core Conclusion
The AI industry is facing a fundamental route divergence:
| Dimension | LLM Route (Mainstream) | JEPA Route (LeCun) |
|---|---|---|
| Core Architecture | Transformer + Next-Token Prediction | Joint Embedding Predictive Architecture |
| Training Method | Massive text generation prediction | World state prediction in joint embedding space |
| Generation Method | Autoregressive token-by-token | Non-generative, reasoning in embedding space |
| Physical Understanding | Implicit learning (may learn) | Explicit encoding (design guarantees) |
| Compute Efficiency | High inference cost (generates one by one) | Fast planning (embedding space operations) |
| Typical Players | OpenAI, Anthropic, Google, Chinese models | Meta (LeCun team) |
In LeCun latest experiment, tiny parameters + single GPU achieved natural physical law encoding + ultra-fast planning. This contrasts sharply with current LLM training requiring hundreds of billions of parameters and tens of thousands of GPUs.
LeCun Core Arguments
LeCun has been repeatedly emphasizing one issue since the early days of the LLM boom:
“If you make the model big enough, it will eventually understand how the world works — this assumption has never been proven.”
His critique can be summarized in three points:
1. Fundamental Defect of Autoregressive Generation
LLMs learn through “predicting the next word,” which means:
- Can only learn statistical patterns of text, cannot truly understand the physical world
- Each generation step depends on the previous one, inference speed grows linearly
- Hallucination problems are rooted in the uncertainty of “next token probability”
2. Advantages of Embedding Space Reasoning
JEPA core idea:
- Encode world states as high-dimensional embedding vectors
- Perform prediction and planning in embedding space
- No need to generate tokens one by one, instead directly manipulate abstract representations
This is similar to how human thinking works — we do not “silently speak word by word” to plan actions, but “imagine” results in an abstract space.
3. Crushing Computational Efficiency Advantage
In LeCun experiment, small parameters + single GPU achieved:
- Ultra-fast planning: embedding space operations are orders of magnitude faster than token-by-token generation
- Physical laws naturally encoded: no extra training needed, the architecture itself tends to learn physical laws
- Low energy consumption: does not rely on massive compute and data
Why Suddenly Getting Attention Now
For the past three years, the LLM route has dominated, drowning out JEPA voices in the Scaling Law celebration. But 2026 has seen some turning points:
| Turning Signal | Meaning |
|---|---|
| GPT-5.5/Claude Opus 4.7 training costs growing exponentially | Scaling Law may be hitting ceiling |
| Four giants AI spending $725B in 2026 | Financial sustainability of compute race in question |
| LeCun experiment achieves physical encoding with small parameters | Another route may actually work |
| Community consensus “LLMs good enough but not good enough” | 90% scenarios LLMs suffice, but key scenarios still have gaps |
Technical Comparison: JEPA vs LLM
LLM Route:
Input text → Tokenize → Transformer layers compute → Generate output token by token → Decode to text
↑ Compute-intensive, expensive at every step
JEPA Route:
Input perception → Encoder extracts embeddings → Predict/plan in embedding space → Decoder outputs
↑ Operates in abstract space, compute dramatically reduced| Capability | LLM | JEPA |
|---|---|---|
| Text Generation | ★★★★★ | ★★ |
| Code Generation | ★★★★★ | ★★ |
| Physical Reasoning | ★★ | ★★★★★ |
| Planning Speed | ★★ | ★★★★★ |
| Training Efficiency | ★★ | ★★★★ |
| Generalization | ★★★★ | ★★★★★ |
Impact on Industry
If JEPA Proves Viable
- AI cost structure will be completely rewritten: no need for tens of thousands of GPUs for training, small/medium companies can also build strong models
- Qualitative change in Agent capabilities: planning and reasoning speed improves by orders of magnitude, truly autonomous agents become possible
- Meta strategic advantage: if JEPA route works, Meta will have a different technological moat from OpenAI/Google
But the Reality Is
- JEPA has so far only shown advantages in specific tasks (physical reasoning, planning)
- In LLM core strength areas like text generation, coding, creative writing, JEPA is far from mature
- From lab to product, JEPA may still need 3-5 years of validation
Action Recommendations
- Researchers: JEPA is a direction worth tracking, but should not abandon LLM route — LLM remains the main force in the short term
- Investors: Watch Meta investment pace in JEPA direction, and whether open source implementations emerge
- Developers: Continue deepening in LLM ecosystem for now, but can experiment with JEPA in planning/physical reasoning scenarios
- Enterprise decision-makers: LLM is already deployable, no need to wait for JEPA — but mark this direction on the technology radar
LeCun is betting that “the entire industry is rolling on one road to the end, while another road might be better.” Whether this bet is correct will have more answers in 2026-2027. But one thing is certain: the AI route debate is far from over.