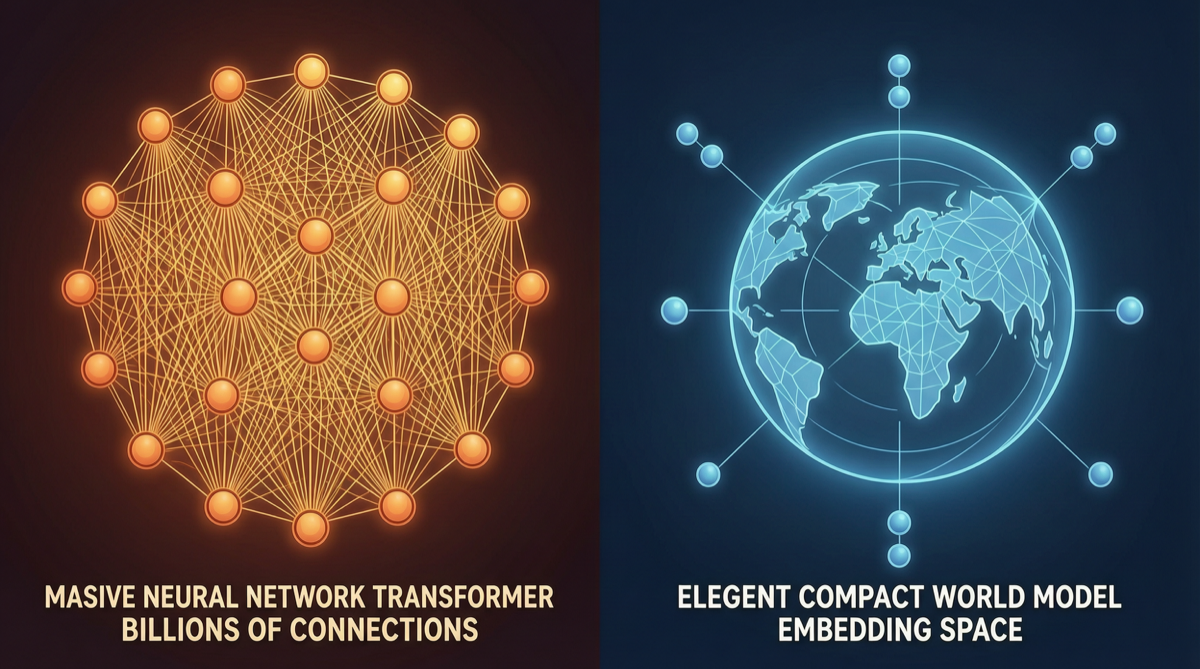
Ключевой вывод
AI-индустрия сталкивается с фундаментальным расхождением маршрутов:
| Параметр | Маршрут LLM (основной) | Маршрут JEPA (ЛеКун) |
|---|---|---|
| Базовая архитектура | Transformer + предсказание следующего токена | Joint Embedding Predictive Architecture |
| Метод обучения | Массовое предсказание генерации текста | Предсказание состояния мира в объединённом пространстве встраиваний |
| Метод генерации | Авторегрессивная токенизация | Негенеративный, рассуждение в пространстве встраиваний |
| Понимание физики | Неявное обучение (может выучить) | Явное кодирование (дизайн гарантирует) |
| Вычислительная эффективность | Высокая стоимость вывода (генерирует по одному) | Быстрое планирование (операции в пространстве встраиваний) |
| Типичные игроки | OpenAI, Anthropic, Google, китайские модели | Meta (команда ЛеКуна) |
В последнем эксперименте ЛеКуна крошечные параметры + один GPU достигли естественного кодирования физических законов + сверхбыстрого планирования. Это резко контрастирует с текущим обучением LLM, требующим сотен миллиардов параметров и десятков тысяч GPU.
Основные аргументы ЛеКуна
ЛеКун с самого начала бума LLM неоднократно подчёркивал одну проблему:
«Если сделать модель достаточно большой, она в конечном итоге поймёт, как устроен мир — это предположение никогда не было доказано.»
Его критику можно свести к трём пунктам:
1. Фундаментальный дефект авторегрессивной генерации
LLM учатся через «предсказание следующего слова», что означает:
- Могут выучить только статистические паттерны текста, не могут по-настоящему понять физический мир
- Каждый шаг генерации зависит от предыдущего, скорость вывода растёт линейно
- Проблемы галлюцинаций коренятся в неопределённости «вероятности следующего токена»
2. Преимущества рассуждения в пространстве встраиваний
Ключевая идея JEPA:
- Кодировать состояния мира как высокоразмерные векторы встраиваний
- Выполнять предсказание и планирование в пространстве встраиваний
- Не нужно генерировать токены по одному, вместо этого напрямую манипулировать абстрактными представлениями
Это похоже на то, как работает человеческое мышление — мы не «произносим слово за словом в уме» для планирования действий, а «представляем» результаты в абстрактном пространстве.
3. Разрушительное преимущество вычислительной эффективности
В эксперименте ЛеКуна малые параметры + один GPU достигли:
- Сверхбыстрого планирования: операции в пространстве встраиваний на порядки быстрее, чем генерация токен за токеном
- Физические законы естественно закодированы: дополнительное обучение не требуется, сама архитектура склонна изучать физические законы
- Низкое энергопотребление: не зависит от массовых вычислений и данных
Почему внезапно привлекает внимание
Последние три года маршрут LLM доминировал, заглушая голоса JEPA в праздновании Scaling Law. Но 2026 год принёс несколько поворотных моментов:
| Поворотный сигнал | Значение |
|---|---|
| Стоимость обучения GPT-5.5/Claude Opus 4.7 растёт экспоненциально | Scaling Law, возможно, достигает потолка |
| Четыре гиганта тратят $725 млрд на AI в 2026 | Финансовая устойчивость гонки вычислений под вопросом |
| Эксперимент ЛеКуна достигает кодирования физики с малыми параметрами | Другой маршрут может действительно работать |
| Консенсус сообщества «LLM достаточно хороши, но недостаточно» | В 90% сценариев LLM хватает, но ключевые сценарии всё ещё имеют пробелы |
Техническое сравнение: JEPA vs LLM
Маршрут LLM:
Входной текст → Токенизация → Вычисление слоёв Transformer → Генерация вывода токен за токеном → Декодирование в текст
↑ Вычислительно интенсивно, дорого на каждом шаге
Маршрут JEPA:
Входное восприятие → Энкодер извлекает встраивания → Предсказание/планирование в пространстве встраиваний → Декодер выводит
↑ Операции в абстрактном пространстве, вычисления значительно сокращены| Способность | LLM | JEPA |
|---|---|---|
| Генерация текста | ★★★★★ | ★★ |
| Генерация кода | ★★★★★ | ★★ |
| Физическое рассуждение | ★★ | ★★★★★ |
| Скорость планирования | ★★ | ★★★★★ |
| Эффективность обучения | ★★ | ★★★★ |
| Обобщение | ★★★★ | ★★★★★ |
Влияние на отрасль
Если JEPA окажется жизнеспособным
- Структура затрат AI будет полностью переписана: не нужны десятки тысяч GPU для обучения, малые и средние компании тоже смогут создавать сильные модели
- Качественное изменение способностей агентов: скорость планирования и рассуждения повышается на порядки, по-настоящему автономные агенты становятся возможными
- Стратегическое преимущество Meta: если маршрут JEPA сработает, Meta будет иметь другой технологический ров от OpenAI/Google
Но реальность такова
- JEPA пока показал преимущества только в конкретных задачах (физическое рассуждение, планирование)
- В ключевых областях силы LLM, таких как генерация текста, кодирование, креативное письмо, JEPA далёк от зрелости
- От лаборатории до продукта JEPA может потребоваться ещё 3-5 лет валидации
Рекомендации к действию
- Исследователи: JEPA — направление, достойное отслеживания, но не следует отказываться от маршрута LLM — LLM остаётся основной силой в краткосрочной перспективе
- Инвесторы: следите за темпами инвестиций Meta в направление JEPA и появлением реализаций с открытым кодом
- Разработчики: продолжайте углубляться в экосистему LLM, но можно экспериментировать с JEPA в сценариях планирования/физического рассуждения
- Корпоративные лица, принимающие решения: LLM уже можно развёртывать, не нужно ждать JEPA — но отметьте это направление на технологическом радаре
ЛеКун делает ставку на то, что «вся отрасль катится по одной дороге до конца, в то время как другая дорога может быть лучше». Правильна ли эта ставка — 2026-2027 годы дадут больше ответов. Но одно точно: спор о маршрутах AI далёк от завершения.