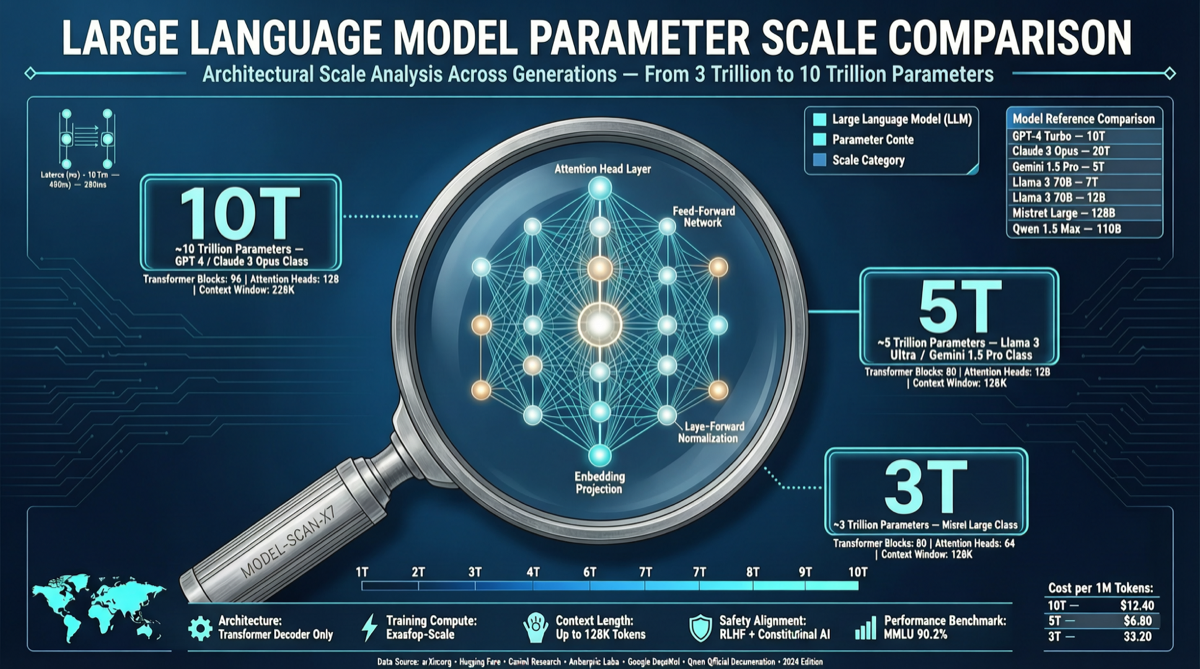
Core Findings
A research team estimated all frontier closed-source LLM parameters using a clever method:
| Model | Estimated Parameters | Method | Confidence |
|---|---|---|---|
| GPT-5.5 | ~10 trillion | Knowledge depth probe | Medium |
| Claude Opus 4.x | ~4-5 trillion | Knowledge depth probe | Medium |
| Grok 4 | ~3 trillion | Knowledge depth probe | Medium |
| Kimi K2.5 | 1 trillion (official) | — | High |
| DeepSeek V4 | 671B (official) | — | High |
Key finding: Closed-source models vary dramatically in parameter scale. GPT-5.5 is about 2x larger than Claude Opus.
”Knowledge Probe” Method
The core idea:
More parameters → More knowledge stored → More obscure questions answerable
Steps:
- Build knowledge gradient question sets from common to extremely niche
- Test accuracy curves across models
- Fit parameter-knowledge relationship using known open-source models as baseline
- Back-calculate closed-source model parameters from knowledge retention rate
What These Numbers Mean
- GPT-5.5 ~10T: 5.7x larger than GPT-4. Explains its 82.7% on Terminal-Bench 2.0
- Claude Opus ~4-5T: Half of GPT-5.5 but still leads in LMSYS Arena Elo (1,503 vs 1,481). Fewer parameters + comparable results = higher efficiency
- Grok 4 ~3T: Smallest of the three, yet xAI ranks second in Arena Elo (1,495)
Methodology Limitations
- Knowledge ≠ Parameters: Better training data or architecture can achieve more with fewer parameters
- MoE complexity: For MoE models, “total” vs “active” parameters differ greatly
- Calibration issues: Open-source basins may not be representative
- Statistical error: Margin of error could be ±30% or more
Why This Research Matters
In an era of closed-source frontier models, researchers lack direct access to model architectures. “Knowledge probe” provides:
- Capability evaluation without API access
- Objective cross-model comparison
- Trend tracking over time
Relationship with Chinese Models
Chinese open-source models publish their parameters transparently (Kimi K2.5, DeepSeek V4, Qwen 3.6). This transparency earns higher credibility in academic and research communities.
Landscape Assessment
The parameter scale race is entering a new phase:
- GPT-5.5’s 10T: OpenAI going far on brute force
- Claude Opus’s 4-5T: Anthropic going precise on efficiency
- Chinese open-source: Transparent parameters + high cost-effectiveness changing the game
Action Recommendations
- Researchers: Build systematic evaluation frameworks based on this method
- Enterprise users: Parameter count isn’t everything — efficiency (results/cost) matters more
- Policymakers: Lack of closed-source model transparency is a systemic risk