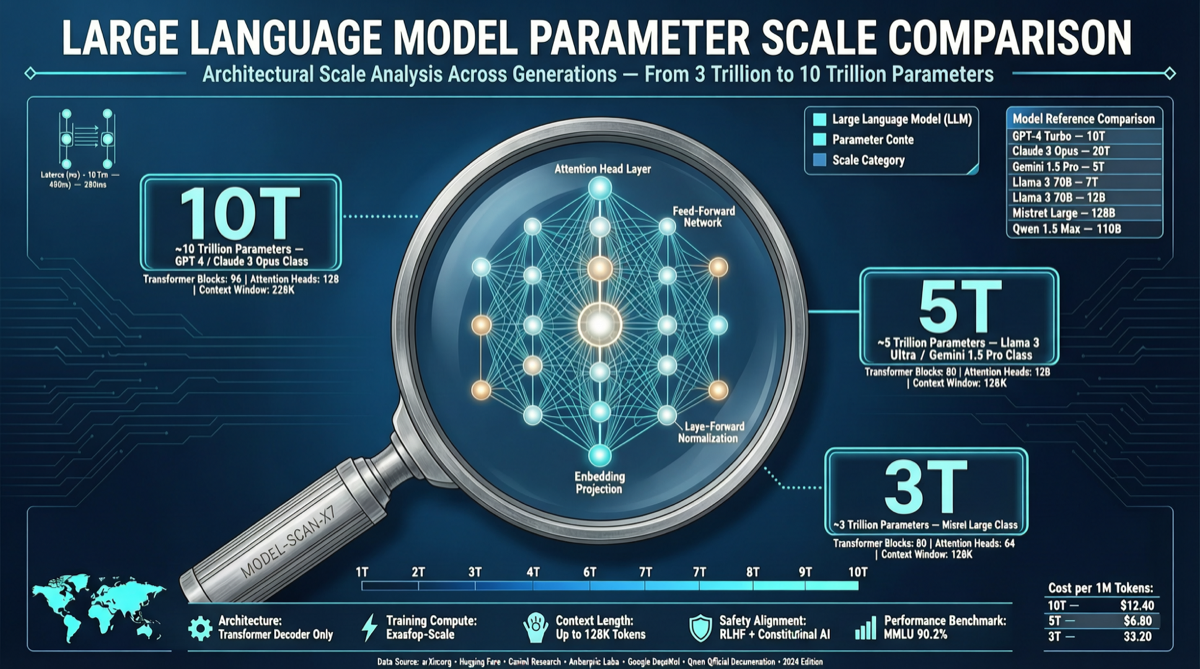
主要な発見
研究チームが巧妙的な手法で全frontierクローズドソースLLMのパラメータを推定:
GPT-5.5 約10兆、Claude Opus 約4-5兆、Grok 4 約3兆。
「知識プローブ」手法
パラメータが多いほど多くの知識を保持し、よりマニアックな質問に答えられるという原理に基づき、オープンソースモデルを基準としてクローズドソースモデルのパラメータを逆算。
数字の意味
- GPT-5.5 約10T:GPT-4の約5.7倍
- Claude Opus 約4-5T:GPT-5.5の半分だがArena Eloでは依然としてリード。効率性の勝利
- Grok 4 約3T:3つのうち最小だがArena Eloで2位
中国モデルとの関係
中国のオープンソースモデル(Kimi K2.5、DeepSeek V4、Qwen 3.6)はパラメータを透明に公開。この透明性が学術コミュニティで高い信頼を得ている。
評価
パラメータ規模競争は新段階へ。OpenAIはbrute force、Anthropicは効率、中国は透明性+コストパフォーマンスで競争。