Conclusion
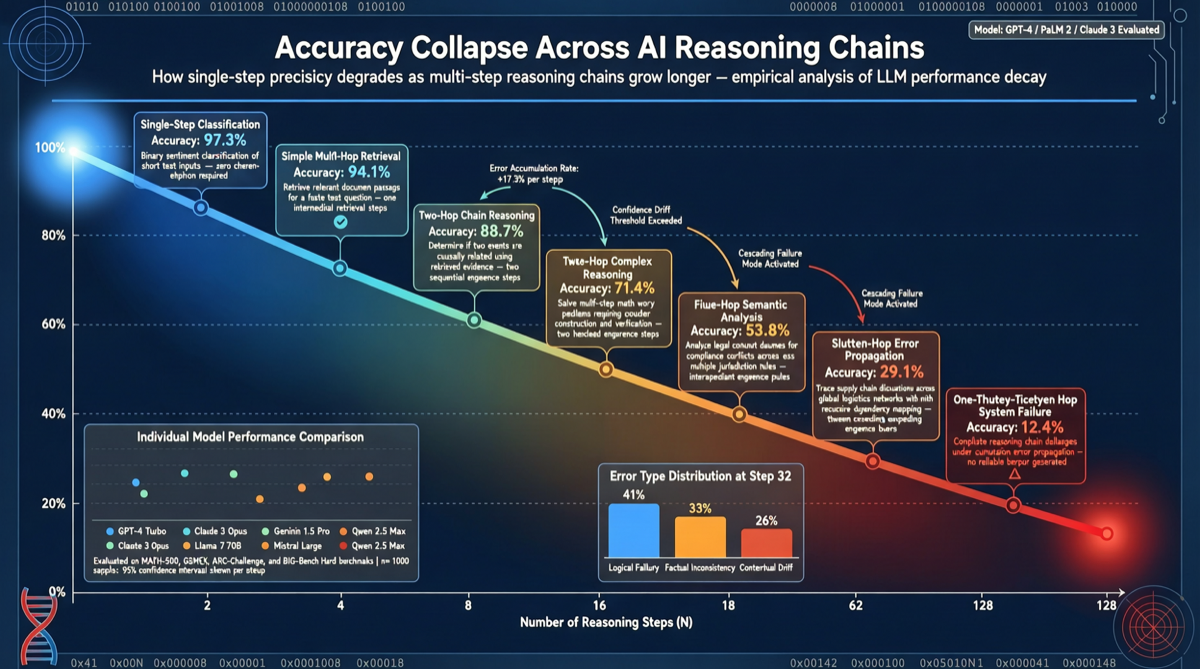
Oxford University and Lawrence Livermore National Laboratory (LLNL) jointly published a benchmark study on long-horizon chain-of-thought reasoning. Using GPT 5.2 as the test subject, the study found that the model achieves 95.7% accuracy on individual problems, but when those same problems are chained into multi-step tasks, accuracy collapses to 9.83%.
This result reveals a core bottleneck of current AI models: strong individual capabilities, but system-level failure due to error accumulation in multi-step chains. The research team notes this is not a problem that can be fixed through simple optimization.
Test Dimensions
Benchmark Design
The research team selected a set of problems that GPT 5.2 can solve independently with 95.7% accuracy. They then organized these problems into a chain requiring sequential completion — where each step’s output serves as the next step’s input.
Result: when these high-accuracy individual tasks were chained together, overall accuracy dropped to 9.83%. Near-perfect capability almost completely fails in multi-step scenarios.
Error Cascading Effect
The accuracy collapse from 95.7% to 9.83% stems from cascading error amplification:
- Even a 4.3% error rate in the first step contaminates the input for all subsequent steps
- As the chain grows, compound error rates increase exponentially
- The model cannot “self-check” and “self-correct” at intermediate steps
Why It “Cannot Be Fixed”
The research team identifies three core reasons:
- Self-attention limitations: Transformer architecture dilutes early-step information through attention weights in later steps when processing long chains
- Lack of intermediate verification: The model does not actively verify output correctness after each step, instead passing results directly to the next step
- Distribution shift: Even with low per-step error rates, the input distribution rapidly diverges from training data distribution after multi-step chaining
Implications for Practical Applications
| Scenario | Risk Level | Explanation |
|---|---|---|
| Single Q&A/analysis | Low | Individual task accuracy remains very high |
| Multi-step workflows | High | Longer chains = higher overall failure rate |
| Autonomous agents | Very high | Agents are essentially long reasoning chains and need additional error recovery mechanisms |
| Scientific discovery pipelines | High | Multi-stage research processes require human intervention at key nodes |
Selection Guidance
- Single-task scenarios: Current models are sufficient — 95.7% accuracy is acceptable in most contexts
- Multi-step workflows: Add human review or cross-validation at critical nodes; do not fully rely on automatic chaining
- Agent development: Must include error detection and fallback mechanisms; do not assume chains will execute smoothly end-to-end
- Research/engineering decisions: Understand the “chain collapse” property of models and set checkpoints in critical processes