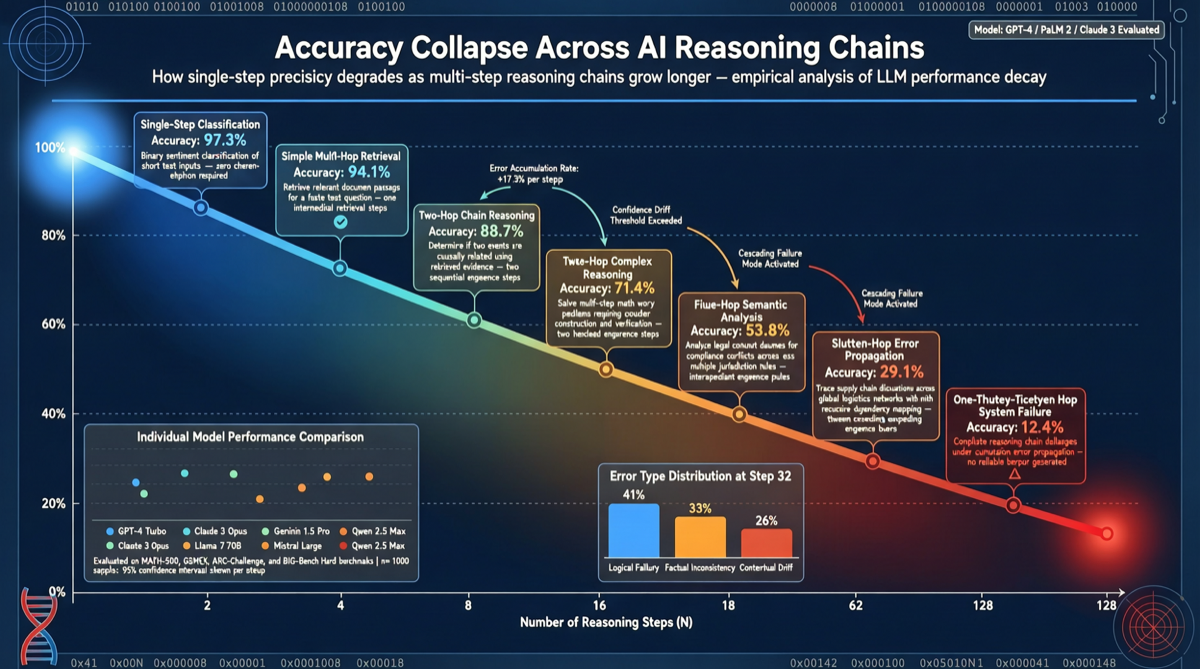
結論
オックスフォード大学とローレンスリバモア国立研究所(LLNL)は、長連鎖推論能力に関するベンチマーク研究を共同発表した。GPT 5.2をテスト対象とした研究では、単体問題におけるモデルの解決率は95.7%に達するが、同じ問題を多段階タスクとして連鎖させた場合、正確率は9.83%に急落した。
この結果は現在のAIモデルのコアボトルネックを明らかにしている:単体能力は強力だが、多段階連鎖において誤差累積がシステムレベルの失敗を引き起こす。研究チームは、これは単純な最適化で修復できる問題ではないと指摘している。
テスト次元
ベンチマーク設計
研究チームは、GPT 5.2が95.7%の正確率で独立して解決できる一連の問題を選定した。随后、これらの問題を順次完了が必要な連鎖として組織化——各ステップの出力が次のステップの入力となる。
結果:これらの高正確率の単体タスクを連鎖させたところ、全体の正確率は9.83%に低下した。ほぼ完璧な能力が多段階シナリオでほぼ完全に失效することを意味する。
誤差累積効果
正確率95.7%から9.83%への急落の根本原因は、誤差のカスケード増幅にある:
- 最初のステップでわずか4.3%のミス率でも、后续のすべてのステップの入力を汚染する
- 連鎖が長くなるにつれて、複合誤差率は指数関数的に上昇
- モデルは中間ステップで「自己検証」や「自己修正」ができない
なぜ「修復不可能」なのか
研究チームは3つの核心的原因を挙げている:
- 自己注意メカニズムの限界:Transformerアーキテクチャは長連鎖を処理する際、早期ステップの情報が后续ステップの注意重みによって希釈される
- 中間検証の欠如:モデルは各ステップ完了後に出力の正確性を積極的に検証せず、直接次のステップに渡す
- 分布シフト:単ステップの誤差率が低くても、多段階連鎖後の入力分布は訓練データ分布から急速に逸脱する
実用化への示唆
| シナリオ | リスクレベル | 説明 |
|---|---|---|
| 単体問答/分析 | 低 | 単体タスクの正確率は依然として非常に高い |
| 多段階ワークフロー | 高 | 連鎖が長いほど、全体の失敗率が高い |
| 自律エージェント | 極めて高い | エージェントは本質的に長連鎖推論であり、追加のエラー回復メカニズムが必要 |
| 科学的発見フロー | 高 | 多段階研究フローは重要なノードで人間の介入が必要 |
選定アドバイス
- 単体タスクシナリオ:現在のモデルで十分——95.7%の正確率はほとんどのシナリオで受け入れ可能
- 多段階ワークフロー:重要なノードで人間のレビューや交差検証を追加し、モデルの自動連鎖に完全に依存しない
- エージェント開発:エラー検出とフォールバックメカニズムを必ず含め、連鎖が最後までスムーズに実行されると仮定しない
- 科学研究/エンジニアリング意思決定:モデルの「連鎖崩壊」特性を理解し、重要なプロセスにチェックポイントを設定