Вывод
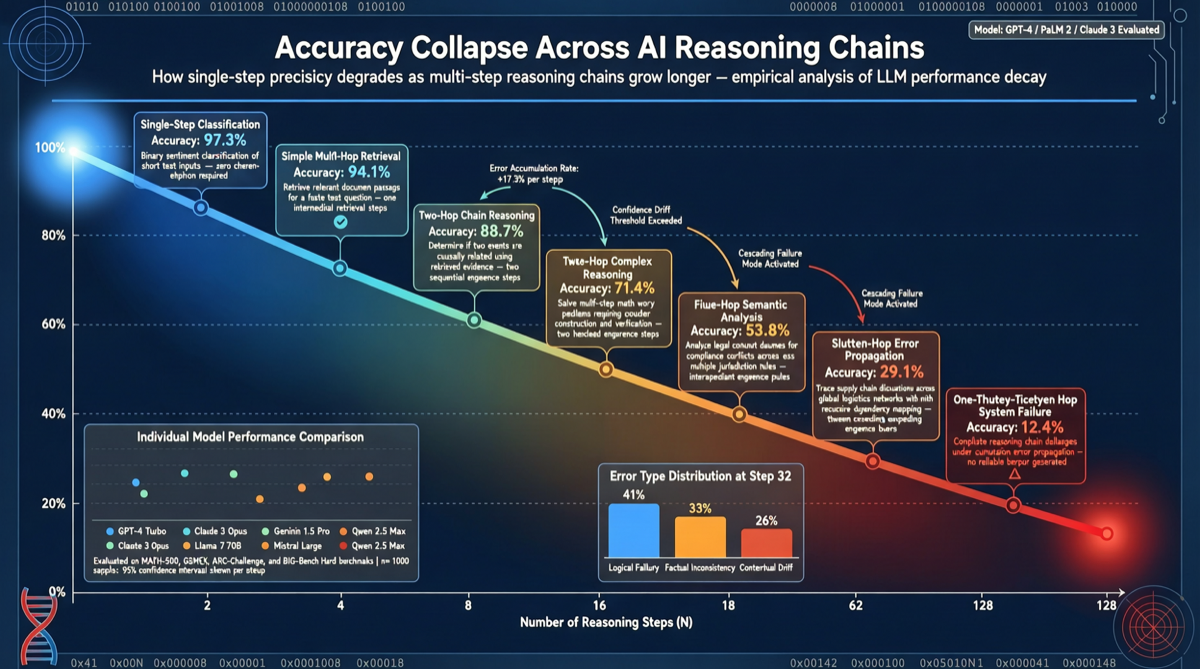
Оксфордский университет и Ливерморская национальная лаборатория (LLNL) совместно опубликовали исследование бенчмарка по длинному цепочечному рассуждению. Используя GPT 5.2 в качестве тестового объекта, исследование показало, что модель достигает 95,7% точности на отдельных задачах, но когда те же задачи объединяются в многошаговые цепочки, точность падает до 9,83%.
Этот результат выявляет ключевое ограничение текущих ИИ-моделей: сильные индивидуальные способности, но системный сбой из-за накопления ошибок в многошаговых цепочках. Исследовательская группа отмечает, что это проблема, которую нельзя исправить простой оптимизацией.
Измерения тестирования
Дизайн бенчмарка
Исследовательская группа отобрала набор задач, которые GPT 5.2 может решать независимо с точностью 95,7%. Затем они организовали эти задачи в цепочку, требующую последовательного выполнения — выход каждого шага становится входом следующего.
Результат: когда эти высокоточные отдельные задачи были объединены в цепочку, общая точность упала до 9,83%. Почти идеальные способности практически полностью失效 в многошаговых сценариях.
Эффект каскадирования ошибок
Падение точности с 95,7% до 9,83% обусловлено каскадным усилением ошибок:
- Даже 4,3% ошибок на первом шаге загрязняет входные данные для всех последующих шагов
- По мере роста цепочки составная частота ошибок возрастает экспоненциально
- Модель не может «самопроверяться» и «самокорректироваться» на промежуточных шагах
Почему это «не исправить»
Исследовательская группа выделяет три ключевые причины:
- Ограничения механизма самовнимания: архитектура Transformer размывает информацию ранних шагов через веса внимания на поздних шагах при обработке длинных цепочек
- Отсутствие промежуточной верификации: модель не проверяет активно корректность вывода после каждого шага, а напрямую передаёт результат следующему шагу
- Сдвиг распределения: даже при низкой частоте ошибок на каждом шаге распределение входных данных после многошагового связывания быстро отклоняется от распределения обучающих данных
Последствия для практического применения
| Сценарий | Уровень риска | Пояснение |
|---|---|---|
| Отдельные вопросы/анализ | Низкий | Точность отдельных задач остаётся очень высокой |
| Многошаговые рабочие процессы | Высокий | Чем длиннее цепочка, тем выше общая частота сбоев |
| Автономные агенты | Очень высокий | Агенты по сути являются длинными цепочками рассуждений и нуждаются в дополнительных механизмах восстановления после ошибок |
| Конвейеры научных открытий | Высокий | Многоэтапные исследовательские процессы требуют человеческого вмешательства на ключевых узлах |
Рекомендации по выбору
- Сценарии отдельных задач: текущих моделей достаточно — 95,7% точности приемлемо в большинстве контекстов
- Многошаговые рабочие процессы: добавляйте человеческую проверку или кросс-валидацию на критических узлах; не полагайтесь полностью на автоматическое связывание
- Разработка агентов: обязательно включайте механизмы обнаружения ошибок и отката; не предполагайте, что цепочки будут выполняться гладко до конца
- Научные/инженерные решения: понимайте свойство «цепочечного коллапса» моделей и устанавливайте контрольные точки в критических процессах